You might also like
- Muôn Kiếp Nhân Sinh 3: Muôn Kiếp Nhân Sinh, #3From EverandMuôn Kiếp Nhân Sinh 3: Muôn Kiếp Nhân Sinh, #3Rating: 5 out of 5 stars5/5 (2)
- Tri Tue Nhan TaoDocument104 pagesTri Tue Nhan TaoTùng Tưng TửngNo ratings yet
- Nhap Mon Tri Tue Nhan TaoDocument171 pagesNhap Mon Tri Tue Nhan Taoapi-3725904No ratings yet
- Nhap Mon Tri Tue Nhan TaoDocument171 pagesNhap Mon Tri Tue Nhan Taoapi-3725904No ratings yet
- Nhập Môn Trí Tuệ Nhân TạoDocument33 pagesNhập Môn Trí Tuệ Nhân TạoLê Minh HưngNo ratings yet
- Lược Sử Ngành Trí Tuệ Nhân TạoDocument7 pagesLược Sử Ngành Trí Tuệ Nhân TạoHAU LE DUCNo ratings yet
- Chap 1Document18 pagesChap 1tailieuhoctaphuuphucNo ratings yet
- Nhóm 9-Báo Cáo AIDocument19 pagesNhóm 9-Báo Cáo AIvuongthang8102003No ratings yet
- Chapter 1-4 ME5667-AI RoboticsDocument220 pagesChapter 1-4 ME5667-AI RoboticsNam HiNo ratings yet
- Nhóm 9-Báo Cáo AI-Đoán SốDocument28 pagesNhóm 9-Báo Cáo AI-Đoán Sốvuongthang8102003No ratings yet
- 3 Chương 1Document6 pages3 Chương 1Nguyễn KhánhNo ratings yet
- Bao Cao Do AnDocument23 pagesBao Cao Do AnNguyễn Văn AnhNo ratings yet
- L1-Gioi Thieu TTNTDocument21 pagesL1-Gioi Thieu TTNThuynhcongchaNo ratings yet
- (123doc) - Ung-Dung-Mang-Tich-Chap-De-Nhan-Biet-Cho-MeoDocument47 pages(123doc) - Ung-Dung-Mang-Tich-Chap-De-Nhan-Biet-Cho-MeoTgdd PhuNo ratings yet
- Nhap Mon Tri Tue Nhan TaoDocument171 pagesNhap Mon Tri Tue Nhan TaoThắ TrầnNo ratings yet
- Chapter 1 4 ME5667 AI Robotics MinDocument213 pagesChapter 1 4 ME5667 AI Robotics MinDương Bá LinhNo ratings yet
- Mối Quan Hệ Về Chất Và Lượng Trong Lịch Sử Phát Triển Trí Tuệ Nhân TạoDocument15 pagesMối Quan Hệ Về Chất Và Lượng Trong Lịch Sử Phát Triển Trí Tuệ Nhân TạoMInh ThanhNo ratings yet
- Bài toán người đi du lịchDocument29 pagesBài toán người đi du lịchHổ Đồng Bằng83% (6)
- Bai Giang TTNT DHKDCN 2013Document67 pagesBai Giang TTNT DHKDCN 2013Đinh ThắmNo ratings yet
- Tailieuxanh TTNT Ngo Huu Phuoc c1 4409Document28 pagesTailieuxanh TTNT Ngo Huu Phuoc c1 4409HoàngNo ratings yet
- Tiểu luận 1Document10 pagesTiểu luận 11986 superujNo ratings yet
- Chapter 1 IntroductionDocument35 pagesChapter 1 IntroductionTrần Văn MạnhNo ratings yet
- Bài 1Document24 pagesBài 1Thanh Thiện Trần ChâuNo ratings yet
- BCTri Tue Nhan TaoDocument23 pagesBCTri Tue Nhan TaoLê HoaNo ratings yet
- Định nghĩa:: Giai đoạn sơ khai của trí tuệ nhân tạoDocument6 pagesĐịnh nghĩa:: Giai đoạn sơ khai của trí tuệ nhân tạoCyn LeeNo ratings yet
- Tuần 1 - Nhóm 3Document4 pagesTuần 1 - Nhóm 3Ý ThươngNo ratings yet
- Lịch Sử AI Qua Các Giai ĐoạnDocument3 pagesLịch Sử AI Qua Các Giai ĐoạnNguyễn Đức PhúcNo ratings yet
- Khái niệm về trí tuệ nhân tạoDocument11 pagesKhái niệm về trí tuệ nhân tạoQuang HuyNo ratings yet
- HTTPWWW Jaist Ac JP BaoWritingsAI50years PDFDocument9 pagesHTTPWWW Jaist Ac JP BaoWritingsAI50years PDFThanh BìnhNo ratings yet
- Nhap Mon Tri Tue Nhan Tao 01092020Document145 pagesNhap Mon Tri Tue Nhan Tao 01092020Hán Ngọc ÁnhNo ratings yet
- AI - 1 - Nhap Mon TTNTDocument8 pagesAI - 1 - Nhap Mon TTNTHoài An NgôNo ratings yet
- 2020-05!11!17!20!44-Giáo Trình Trí Tuệ Nhân Tạo 2Document165 pages2020-05!11!17!20!44-Giáo Trình Trí Tuệ Nhân Tạo 2Linh ChuNo ratings yet
- Full Slide AIDocument422 pagesFull Slide AITrần Văn MạnhNo ratings yet
- Artificial Intelligence PDFDocument152 pagesArtificial Intelligence PDFVotri LuanNo ratings yet
- Công nghệ thông tin và giá trị đạo đứcDocument38 pagesCông nghệ thông tin và giá trị đạo đứcStruct DesignProNo ratings yet
- Năm-điều-rút-ra-từ-cuốn-sách-Trí-tuệ-nhân-tạo_-Hướng-dẫn-về-tư-duy-con-ngườiDocument3 pagesNăm-điều-rút-ra-từ-cuốn-sách-Trí-tuệ-nhân-tạo_-Hướng-dẫn-về-tư-duy-con-ngườingankim61knNo ratings yet
- trí tuệ nhân tạo nội dung thi gkDocument9 pagestrí tuệ nhân tạo nội dung thi gkĐăng Trần BáNo ratings yet
- I. Khái niệm AI: Trí tuệDocument8 pagesI. Khái niệm AI: Trí tuệMinh Nhựt Trần ThếNo ratings yet
- AI (1)Document3 pagesAI (1)tanbaolay102No ratings yet
- L1-Gioi-thieu Về Trí Tuệ Nhân TạoDocument19 pagesL1-Gioi-thieu Về Trí Tuệ Nhân Tạohoangcongtu2409No ratings yet
- L1-Gioi-thieu Về Trí Tuệ Nhân TạoDocument19 pagesL1-Gioi-thieu Về Trí Tuệ Nhân Tạothanhdong1311maNo ratings yet
- 02 - Du Lieu Danh Dang Ky Tu Doan123Document1 page02 - Du Lieu Danh Dang Ky Tu Doan123Hòa TrầnNo ratings yet
- Đề cương chi tiếtDocument26 pagesĐề cương chi tiếthungnguyn20No ratings yet
- Nhóm-4 TTNTDocument28 pagesNhóm-4 TTNTLê HoaNo ratings yet
- Báo cáo Nhập môn Trí tuệ Nhân tạo QuangToànDocument22 pagesBáo cáo Nhập môn Trí tuệ Nhân tạo QuangToànQuốc ToànNo ratings yet
- Bài Giảng Môn Học: Trí Tuệ Nhân TạoDocument105 pagesBài Giảng Môn Học: Trí Tuệ Nhân TạoNguyễn LiêmNo ratings yet
- NHDocument15 pagesNHTrần Nhật CườngNo ratings yet
- M NG NG NghĩaDocument23 pagesM NG NG Nghĩathach1911100% (2)
- Dlbook Chap01Document29 pagesDlbook Chap01thuyanhnguyen164.workNo ratings yet
- TTNT 01Document19 pagesTTNT 01lsdjf abcNo ratings yet
- Machine Learning Dang Quang HuyDocument59 pagesMachine Learning Dang Quang Huythodz03vhNo ratings yet
- Hướng dẫn Tiền điện tử: Hướng dẫn cho người mới bắt đầu về Tiền điện tử, Blockchain và NFTFrom EverandHướng dẫn Tiền điện tử: Hướng dẫn cho người mới bắt đầu về Tiền điện tử, Blockchain và NFTNo ratings yet
- Xây dựng bảng factDocument5 pagesXây dựng bảng factTan CuongNo ratings yet
- Thuat Ngu Tieng Anh Chuyen Nganh Ke Toan Tai Chinh - Gop FileDocument1,281 pagesThuat Ngu Tieng Anh Chuyen Nganh Ke Toan Tai Chinh - Gop FileTan CuongNo ratings yet
- (VIE) Gaming Influencer MarketingDocument29 pages(VIE) Gaming Influencer MarketingTan CuongNo ratings yet
- (MẪU) - (ÁP DỤNG TỪ T09.2019) - ĐƠN XIN PHÉP NGHỈ - SEATEKDocument1 page(MẪU) - (ÁP DỤNG TỪ T09.2019) - ĐƠN XIN PHÉP NGHỈ - SEATEKTan CuongNo ratings yet
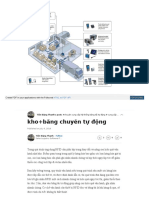
- Hệ thống RFID trong nhà kho+băng chuyền tự độngDocument5 pagesHệ thống RFID trong nhà kho+băng chuyền tự độngTan CuongNo ratings yet
- Chuong 5 định giá chứng khoánDocument59 pagesChuong 5 định giá chứng khoánTan CuongNo ratings yet
- Phân tích khối lượng công việc phòng Nhân Sự - v4 - SharedDocument10 pagesPhân tích khối lượng công việc phòng Nhân Sự - v4 - SharedTan CuongNo ratings yet
- Sale SampleDocument114 pagesSale SampleTan CuongNo ratings yet
- Chương 5 - TCDN Nâng CaoDocument32 pagesChương 5 - TCDN Nâng Caothang nguyenNo ratings yet
- Du Lieu Don - Bigdata PDFDocument306 pagesDu Lieu Don - Bigdata PDFVõ Văn ThươngNo ratings yet
- DPA7 - One Stop Shop BankingDocument35 pagesDPA7 - One Stop Shop BankingTan CuongNo ratings yet
- Hạch Toán Nghiệp Vụ Doanh Thu Dịch Vụ Và Giá Thành Công TrìnhDocument4 pagesHạch Toán Nghiệp Vụ Doanh Thu Dịch Vụ Và Giá Thành Công TrìnhTan CuongNo ratings yet
- Huong Dan Can Ban Ve Cac Chi So Agile PDFDocument16 pagesHuong Dan Can Ban Ve Cac Chi So Agile PDFTan CuongNo ratings yet
- Cách Xác Định Stakeholder Và Làm Việc Với Stakeholder Của Một Business AnalystDocument11 pagesCách Xác Định Stakeholder Và Làm Việc Với Stakeholder Của Một Business AnalystTan CuongNo ratings yet
- CFOVietnam - Newsletter - Apr-2019 (Final) PDFDocument28 pagesCFOVietnam - Newsletter - Apr-2019 (Final) PDFTan CuongNo ratings yet