You might also like
- College Adjustment Scale (CAS)Document7 pagesCollege Adjustment Scale (CAS)Bianca CarmenNo ratings yet
- Psych StatsDocument322 pagesPsych StatsAleah RodrigoNo ratings yet
- CHAPTER 2 Normal DistributionDocument55 pagesCHAPTER 2 Normal DistributionMissEu Ferrer MontericzNo ratings yet
- Division NAT Diagnostic Test - 40 Items With D.O LogoDocument3 pagesDivision NAT Diagnostic Test - 40 Items With D.O LogoRodolfo Esmejarda Laycano Jr.No ratings yet
- Technical Tables for Schools and Colleges: The Commonwealth and International Library Mathematics DivisionFrom EverandTechnical Tables for Schools and Colleges: The Commonwealth and International Library Mathematics DivisionNo ratings yet
- OLSAT of First Year BSIT Students and Their Relationship To Academic Performance in The College of ICTDocument10 pagesOLSAT of First Year BSIT Students and Their Relationship To Academic Performance in The College of ICTAriel Sumagaysay100% (1)
- 1) Objective: 2) Formula Used 3) Excel Options 4) Procedure: Pivot TableDocument6 pages1) Objective: 2) Formula Used 3) Excel Options 4) Procedure: Pivot TableSurabhi YadavNo ratings yet
- Free Downloadable Brain Technologies Inc. CalendarDocument1 pageFree Downloadable Brain Technologies Inc. CalendarRodrigue ISHIMWENo ratings yet
- Citizen Matters Calendar 2011Document1 pageCitizen Matters Calendar 2011Citizen MattersNo ratings yet
- Work Sheet For 7 QC ToolsDocument4 pagesWork Sheet For 7 QC ToolsDFLQMSNo ratings yet
- Event Schedule Planner: Project/Event Name: Organizer's NameDocument1 pageEvent Schedule Planner: Project/Event Name: Organizer's NameMichael GDNo ratings yet
- Lab Result (Part 22-23-24)Document79 pagesLab Result (Part 22-23-24)Wan Mohamad Noor Hj IsmailNo ratings yet
- Report MRA Maret 2023Document8 pagesReport MRA Maret 2023Dian PrimadonnaNo ratings yet
- RevenueDocument9 pagesRevenueMustameer KhanNo ratings yet
- EEB 525 Lab 1 - 2024Document4 pagesEEB 525 Lab 1 - 2024Melissa MmatliNo ratings yet
- Tnswan Telephone Directory: Pre - AmbleDocument88 pagesTnswan Telephone Directory: Pre - AmbleNalla ThambiNo ratings yet
- App Deployment: Acquisition Market Share Relevant Event Name Strategy MeetingDocument12 pagesApp Deployment: Acquisition Market Share Relevant Event Name Strategy MeetingSaleem Farhan 1931180030No ratings yet
- Cah Kit Control c1 & c2 634986 (January 29-30, 2015)Document19 pagesCah Kit Control c1 & c2 634986 (January 29-30, 2015)Timothy John ValenciaNo ratings yet
- Philips mcm3000 SMDocument27 pagesPhilips mcm3000 SMTito PeñaNo ratings yet
- You Can Use Microsoft Excel But Using The Formulas Given Are Prohibited (Only Adding Columns For Calculation Is Allowed)Document2 pagesYou Can Use Microsoft Excel But Using The Formulas Given Are Prohibited (Only Adding Columns For Calculation Is Allowed)Undecima KontrasNo ratings yet
- PGP Animation ModulesDocument1 pagePGP Animation ModulesSatish BNo ratings yet
- Problem 1 024Document3 pagesProblem 1 024imadusNo ratings yet
- SPC SimplifiedDocument21 pagesSPC Simplifiedpeter25munchenNo ratings yet
- MT2 QZDocument6 pagesMT2 QZAhmed SouissiNo ratings yet
- MPS CompTech9Document44 pagesMPS CompTech9Norilyn TorresNo ratings yet
- Pocketmod - The Free Recyclable Personal OrganizerDocument1 pagePocketmod - The Free Recyclable Personal OrganizerkwaughNo ratings yet
- KLSmartin ME MB3Document16 pagesKLSmartin ME MB3Solomon YimerNo ratings yet
- Me MB 3Document16 pagesMe MB 3amjad aliNo ratings yet
- Bihar Sarkar Sewak CalenderDocument1 pageBihar Sarkar Sewak CalenderNeel KamalNo ratings yet
- Effect Towards Students' Achievements in Education? This Question Requires Analysis of TheDocument2 pagesEffect Towards Students' Achievements in Education? This Question Requires Analysis of TheKavitha SugumaranNo ratings yet
- The 2011 Session Calendar: JanuaryDocument2 pagesThe 2011 Session Calendar: JanuaryKanu HawaiiNo ratings yet
- Ecdis SW InfoDocument213 pagesEcdis SW InfoParul MehtaNo ratings yet
- CLASS XII-A 2021-22 Unit Test I Consolidated ListDocument4 pagesCLASS XII-A 2021-22 Unit Test I Consolidated ListAman JaiswalNo ratings yet
- 10-17-23 Qaqc - Handover Monitoring and Making GoodDocument16 pages10-17-23 Qaqc - Handover Monitoring and Making Goodzyrareynesh02No ratings yet
- STA-201-OL010 - Practice Exercise 1Document6 pagesSTA-201-OL010 - Practice Exercise 1donaldNo ratings yet
- FF 41t18rs4605483Document29 pagesFF 41t18rs4605483rkNo ratings yet
- LS TimetableDocument1 pageLS TimetableRikiMaroNo ratings yet
- 12th MATH NCERT DATADocument1 page12th MATH NCERT DATASimran Kumari GuptaNo ratings yet
- Result of III B.Tech II Semester R20 R19 R16 Supplementary Examinations Dec 2023Document2 pagesResult of III B.Tech II Semester R20 R19 R16 Supplementary Examinations Dec 2023VijayKumarTirupathiNo ratings yet
- Item Analysis RAT IntermediateDocument6 pagesItem Analysis RAT IntermediateAriel DulvaNo ratings yet
- Math Most Important ChaptersDocument1 pageMath Most Important ChaptersVISHNU PRIYA BUDDANINo ratings yet
- 1ST Quarter MPSDocument8 pages1ST Quarter MPSMark Elvin RagosNo ratings yet
- Activity #1: LEBOSADA, NICOLE A. STT041 Frequency DistributionsDocument2 pagesActivity #1: LEBOSADA, NICOLE A. STT041 Frequency DistributionsZech PackNo ratings yet
- Item Analysis Grade 10 Fourth Periodic Test 2022 2023Document1 pageItem Analysis Grade 10 Fourth Periodic Test 2022 2023RONA ANDREA TAMAYONo ratings yet
- 3 1 ResultsDocument16 pages3 1 ResultsSushNo ratings yet
- 2-1 MID-II TimeTableDocument1 page2-1 MID-II TimeTableK V BALARAMAKRISHNANo ratings yet
- TALLER 6 ProbabilidadDocument16 pagesTALLER 6 ProbabilidadNoemy RomeroNo ratings yet
- WS 237Document3 pagesWS 237Prabha KaranNo ratings yet
- Chapter 23 Data Handling-I (Classification and Tabulation of Data) - WatermarkDocument15 pagesChapter 23 Data Handling-I (Classification and Tabulation of Data) - WatermarkSarthakk MittalNo ratings yet
- Fe 3163Document10 pagesFe 3163nor fazlinaNo ratings yet
- Course Plan - CIM - VI PEDocument1 pageCourse Plan - CIM - VI PEarpitb211219peNo ratings yet
- Code Eac NaceDocument2 pagesCode Eac NaceEvan BuwanaNo ratings yet
- Item Analysis Old Grade 10 Second Periodic Test 2022 2023Document1 pageItem Analysis Old Grade 10 Second Periodic Test 2022 2023RONA ANDREA TAMAYONo ratings yet
- Result of III B.Tech I Semester (R19R20) Regular Supplementary Examinations, July-2023Document21 pagesResult of III B.Tech I Semester (R19R20) Regular Supplementary Examinations, July-2023Sai Hari Nath ReddyNo ratings yet
- S3 Btech 1Document1 pageS3 Btech 1Vardhan MNo ratings yet
- Crashes Deaths Crashes Deaths Crashes Deaths Crashes Deaths: Table 1: DigestDocument5 pagesCrashes Deaths Crashes Deaths Crashes Deaths Crashes Deaths: Table 1: DigestNBC MontanaNo ratings yet
- Complete Roadmap To Score 240+ Marks in JEE 2024 - Bahubali StrategyDocument28 pagesComplete Roadmap To Score 240+ Marks in JEE 2024 - Bahubali StrategyHappy HomeNo ratings yet
- ITEM or SKILL ANALYSIS (LIM AO)Document2 pagesITEM or SKILL ANALYSIS (LIM AO)parrochonorilyn6No ratings yet
- III B.Tech 2023-24 Odd Sem End Semester Makeup-Supplementary ExaminationsDocument1 pageIII B.Tech 2023-24 Odd Sem End Semester Makeup-Supplementary ExaminationsgokulkalairajNo ratings yet
- Calendar FY23Document1 pageCalendar FY23oscar veraNo ratings yet
- Exploded View Parts For Model PAC12037 220 230V, 60Hz: Indoor UnitDocument2 pagesExploded View Parts For Model PAC12037 220 230V, 60Hz: Indoor UnitValnir PaixãoNo ratings yet
- JEE 2024 Best Time Table To Score 220+ %ile in First Attempt GueranteedDocument60 pagesJEE 2024 Best Time Table To Score 220+ %ile in First Attempt Gueranteedharsh.mahori09No ratings yet
- Addmath SbaDocument5 pagesAddmath Sbaffiregod849No ratings yet
- Math Rda Item AnalysisDocument3 pagesMath Rda Item AnalysisMarjorie De GuzmanNo ratings yet
- Formative Assessment 4Document2 pagesFormative Assessment 4Aries BerbieNo ratings yet
- Cognitive Psych - RodrigoDocument3 pagesCognitive Psych - RodrigoAleah RodrigoNo ratings yet
- Activity 11 - RodrigoDocument3 pagesActivity 11 - RodrigoAleah RodrigoNo ratings yet
- AmericanizationDocument3 pagesAmericanizationAleah RodrigoNo ratings yet
- Output No. 2 - Frequency DistributionDocument2 pagesOutput No. 2 - Frequency DistributionAleah RodrigoNo ratings yet
- (Rodrigo) Intelligence and NeuroscienceDocument8 pages(Rodrigo) Intelligence and NeuroscienceAleah RodrigoNo ratings yet
- Central Tendency: PSYCH-BC 212 Psychological StatisticsDocument162 pagesCentral Tendency: PSYCH-BC 212 Psychological StatisticsAleah RodrigoNo ratings yet
- Module - 1, Continued. Traffic Parameter Studies and AnalysisDocument18 pagesModule - 1, Continued. Traffic Parameter Studies and AnalysisPraveen M balaramNo ratings yet
- Stan ScoreDocument3 pagesStan ScorehappydentistNo ratings yet
- SolutionDocument243 pagesSolutionxandercageNo ratings yet
- M. A. Part I Semester I by Balaji NiwlikarDocument35 pagesM. A. Part I Semester I by Balaji NiwlikarSonaliNo ratings yet
- Weight-For-Height BOYS: 2 To 5 Years (Percentiles)Document5 pagesWeight-For-Height BOYS: 2 To 5 Years (Percentiles)Marlon Cajas ChicaizaNo ratings yet
- Degree DayDocument17 pagesDegree DayWaqar HassanNo ratings yet
- CDO Commands and Usage DetailsDocument34 pagesCDO Commands and Usage Detailsguru_maheshNo ratings yet
- CPM Scoring Sheet and NormDocument5 pagesCPM Scoring Sheet and NormPankhuri MishraNo ratings yet
- Social Learning and Corporate Peer EffectsDocument17 pagesSocial Learning and Corporate Peer EffectsAlfaez RidhoNo ratings yet
- Math10 Q4 Ver4 Mod3Document31 pagesMath10 Q4 Ver4 Mod3Reyzell Mae L. CastilloNo ratings yet
- Descriptive Statistics - SPSS Annotated OutputDocument13 pagesDescriptive Statistics - SPSS Annotated OutputLAM NGUYEN VO PHINo ratings yet
- Week 5Document55 pagesWeek 5Yumi Ryu TatsuNo ratings yet
- Lesson Plan in Mathematics 10: Mary Elaine R. GundoyDocument3 pagesLesson Plan in Mathematics 10: Mary Elaine R. GundoyFERWINA SANCHEZ0% (1)
- Semi Detailed Lesson PlanDocument3 pagesSemi Detailed Lesson PlanJohn VersonNo ratings yet
- Stevens 1946Document5 pagesStevens 1946Oliwia DubeltowiczNo ratings yet
- Methods For Describing Sets of DataDocument47 pagesMethods For Describing Sets of Datamages87No ratings yet
- Lesson 4 - Standard Normal DistributionDocument26 pagesLesson 4 - Standard Normal Distributionktamog16No ratings yet
- Measures of VariabilityDocument7 pagesMeasures of VariabilityAngelica FloraNo ratings yet
- Fuertes Et Al 2012 A Meta-Analysis of The Effects of Speakers Accents - CleanDocument16 pagesFuertes Et Al 2012 A Meta-Analysis of The Effects of Speakers Accents - CleanYq WanNo ratings yet
- Chapter 10 - Data Analysis and Statistics Practice WorksheetDocument6 pagesChapter 10 - Data Analysis and Statistics Practice WorksheetGreEdgeNo ratings yet
- HEC-RAS 2D Sediment Technical Reference (Beta) PDFDocument122 pagesHEC-RAS 2D Sediment Technical Reference (Beta) PDFpetri30No ratings yet
- Standard Scores and The Normal Curve: Study GuideDocument51 pagesStandard Scores and The Normal Curve: Study GuideHannah Gliz PantoNo ratings yet
- Frequently Asked Questions Equating of Scores On Multiple FormsDocument6 pagesFrequently Asked Questions Equating of Scores On Multiple FormsDeveshKumarNo ratings yet
- 1 s2.0 S0169814107001709 MainDocument8 pages1 s2.0 S0169814107001709 MainMohamed MansourNo ratings yet
- Data AnalysisDocument85 pagesData AnalysisLuuly PhamnguyenNo ratings yet
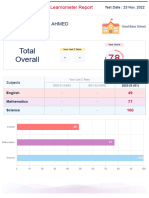
- XSEED Learnometer 2022 Grade 1 BK 6548 H 1669408344558-1669408354008Document2 pagesXSEED Learnometer 2022 Grade 1 BK 6548 H 1669408344558-1669408354008Sharfraz YaseenNo ratings yet