You might also like
- Pima Indian Diabetes QuestionsDocument6 pagesPima Indian Diabetes QuestionsAMAN PRAKASHNo ratings yet
- Savage Worlds - Unofficial New HindrancesDocument3 pagesSavage Worlds - Unofficial New HindrancesLeandro MandoNo ratings yet
- SHO Paper 2Document9 pagesSHO Paper 2Kenny Low100% (1)
- Medical Abbreviations: White Blood Cells: WBC 15. Bedrest: BR 6Document5 pagesMedical Abbreviations: White Blood Cells: WBC 15. Bedrest: BR 6Muhammad Farhan Rizqullah100% (1)
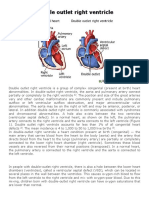
- Case Study: Double Outlet Right VentricleDocument6 pagesCase Study: Double Outlet Right VentriclejisooNo ratings yet
- ML - Workshop - Day2 - Jupyter NotebookDocument15 pagesML - Workshop - Day2 - Jupyter NotebookAbhisingNo ratings yet
- Diabetes Diagrama de ArbolDocument4 pagesDiabetes Diagrama de ArbolRamón MendozaNo ratings yet
- Diabetes Diagrama de ArbolDocument4 pagesDiabetes Diagrama de ArbolRamón MendozaNo ratings yet
- Name: Yandrapu Manoj Naidu Roll No: 20MDT1017: Choose FilesDocument7 pagesName: Yandrapu Manoj Naidu Roll No: 20MDT1017: Choose FilesYANDRAPU MANOJ NAIDU 20MDT1017No ratings yet
- Healthcare PGP - Capstone ProjectDocument32 pagesHealthcare PGP - Capstone ProjectSneh Prakhar0% (1)
- Diabetes Prediction SystemDocument4 pagesDiabetes Prediction Systemsaurabh khairnarNo ratings yet
- Pima Indian Diabetes Questions-1Document1 pagePima Indian Diabetes Questions-1Sayan PalNo ratings yet
- Healthcare PGPDocument28 pagesHealthcare PGPSneh PrakharNo ratings yet
- Step-By-Step-Diabetes-Classification-Knn-Detailed-Copy1 - Jupyter NotebookDocument12 pagesStep-By-Step-Diabetes-Classification-Knn-Detailed-Copy1 - Jupyter NotebookElyzaNo ratings yet
- Diabetis ProjectDocument7 pagesDiabetis ProjectKeerthi SankaraNo ratings yet
- Data PengamatanDocument3 pagesData Pengamatannatasya khairunnisaNo ratings yet
- Capstone Project 2Document15 pagesCapstone Project 2DavidNo ratings yet
- Name: MANOGNA GV Email Id: Major Project: Diabetes Prediction Let's Import Required Libraries!Document4 pagesName: MANOGNA GV Email Id: Major Project: Diabetes Prediction Let's Import Required Libraries!Manogna GvNo ratings yet
- Foodlog Date 2 3 22 - Daily IntakeDocument1 pageFoodlog Date 2 3 22 - Daily Intakeapi-593701830No ratings yet
- Univariate and Multivariate Analysis - Jupyter NotebookDocument5 pagesUnivariate and Multivariate Analysis - Jupyter NotebookAnuvidyaKarthiNo ratings yet
- Mean Vector and Correlation Matrix in R - Jupyter NotebookDocument7 pagesMean Vector and Correlation Matrix in R - Jupyter NotebookAnuvidyaKarthiNo ratings yet
- Diabetes ModelDocument44 pagesDiabetes Modelsasda100% (1)
- Thursday Feb 1Document4 pagesThursday Feb 1api-397151182No ratings yet
- String ResonantDocument3 pagesString ResonantSingh IndrajeetNo ratings yet
- Thursday1-27-22 - Daily IntakeDocument1 pageThursday1-27-22 - Daily Intakeapi-595317201No ratings yet
- Foodlog Date 1-22-22 - Daily IntakeDocument1 pageFoodlog Date 1-22-22 - Daily Intakeapi-599680134No ratings yet
- Tre Project PcuDocument11 pagesTre Project Pcugoo odNo ratings yet
- Foodlog Date 2 3 2024 - Daily IntakeDocument1 pageFoodlog Date 2 3 2024 - Daily Intakeapi-732045328No ratings yet
- Diabetes Prediction - Logistic Regression - Jupyter NotebookDocument4 pagesDiabetes Prediction - Logistic Regression - Jupyter NotebooksaravanakumarNo ratings yet
- Food Log Date 220124Document4 pagesFood Log Date 220124api-593711305No ratings yet
- Foodlog Date February 14 - Daily IntakeDocument1 pageFoodlog Date February 14 - Daily Intakeapi-732764034No ratings yet
- SVM - RF - Diabetes - CSV - 26 - 6 - 2023.ipynb - ColaboratoryDocument8 pagesSVM - RF - Diabetes - CSV - 26 - 6 - 2023.ipynb - Colaboratoryutsavarora1912No ratings yet
- Foodlog Date 2 11 24 - Daily IntakeDocument1 pageFoodlog Date 2 11 24 - Daily Intakeapi-732045328No ratings yet
- Diabetic Prediction Using LogicalRegressionDocument9 pagesDiabetic Prediction Using LogicalRegressionYagnesh VyasNo ratings yet
- Mechelleg-Foodlog Date Sunday 2-11-24 - Daily IntakeDocument1 pageMechelleg-Foodlog Date Sunday 2-11-24 - Daily Intakeapi-732565843No ratings yet
- Copy of Day 2 - Sheet1 3Document1 pageCopy of Day 2 - Sheet1 3api-349309070No ratings yet
- Foodlog Date 2Document1 pageFoodlog Date 2api-595312194No ratings yet
- Foodlog Date Thursday February 9thDocument4 pagesFoodlog Date Thursday February 9thapi-654020081No ratings yet
- Kevin Soto Foodlog Date 2 9 - Daily Intake 1Document1 pageKevin Soto Foodlog Date 2 9 - Daily Intake 1api-732087714No ratings yet
- Day 10 2-7Document2 pagesDay 10 2-7api-396938345No ratings yet
- 2 1 22 - Daily IntakeDocument2 pages2 1 22 - Daily Intakeapi-595126701No ratings yet
- Ms (%) Ed (Kcal/Kg) PC (%) Proteina Animapd (%) FC (%) Ee (%)Document20 pagesMs (%) Ed (Kcal/Kg) PC (%) Proteina Animapd (%) FC (%) Ee (%)JUAN FERNANDO SEGURA CASTRONo ratings yet
- VARIANZADocument4 pagesVARIANZAGERALDINE ESTEFANIA CUELLO PEREZNo ratings yet
- Conversion FactorDocument110 pagesConversion FactorAmanNo ratings yet
- 3rekap Status Gizi 2023Document17 pages3rekap Status Gizi 2023yurna betty kesgagizi kab.pesbar LampungNo ratings yet
- Tablas Vel Vs DosisDocument10 pagesTablas Vel Vs DosisHemir Ariel Jaque BeltranNo ratings yet
- Ikan Ke PT BT VS VL VM DKL %Document3 pagesIkan Ke PT BT VS VL VM DKL %melisa bayu prasetyaNo ratings yet
- Ikan Ke PT BT VS VL VM DKL %Document3 pagesIkan Ke PT BT VS VL VM DKL %melisa bayu prasetyaNo ratings yet
- Foodlog Date 2Document1 pageFoodlog Date 2api-595312194No ratings yet
- Foodlog Date 02 04 24Document1 pageFoodlog Date 02 04 24api-732738212No ratings yet
- Pasta US - AdjDocument9 pagesPasta US - AdjMeshack MateNo ratings yet
- Tue Feb 6 3Document3 pagesTue Feb 6 3api-398289109No ratings yet
- Diagnosa PTM Asik NewDocument8 pagesDiagnosa PTM Asik NewHendra FitriadiNo ratings yet
- Experiment 4Document5 pagesExperiment 4Apurva PatilNo ratings yet
- Friday Feb 9Document3 pagesFriday Feb 9api-397151182No ratings yet
- Age Outlier BMI Outlier Glucose Outlier Insulin Outlier Homa OutlierDocument5 pagesAge Outlier BMI Outlier Glucose Outlier Insulin Outlier Homa OutlierAhmadKomarudinNo ratings yet
- Brand Loyalty Data Logistic RegressionDocument4 pagesBrand Loyalty Data Logistic Regressionritesh choudhuryNo ratings yet
- Foodlog Date 2 01 2022 - Daily IntakeDocument1 pageFoodlog Date 2 01 2022 - Daily Intakeapi-593674825No ratings yet
- Day 7 2-4 WeekendDocument2 pagesDay 7 2-4 Weekendapi-396938345No ratings yet
- Anexo #01 Cálculo de Caída de Tensión Circuitos en Media TensiónDocument69 pagesAnexo #01 Cálculo de Caída de Tensión Circuitos en Media TensiónLuis AngelNo ratings yet
- Foodlog Day 1Document4 pagesFoodlog Day 1api-397125493No ratings yet
- Food Log Date 220126Document4 pagesFood Log Date 220126api-593711305No ratings yet
- Datos Empleados Fabsoluta Facumulada Frelativa Facumulada2 IntervalosDocument6 pagesDatos Empleados Fabsoluta Facumulada Frelativa Facumulada2 IntervalosAlejandro MalagonNo ratings yet
- Math Practice Simplified: Decimals & Percents (Book H): Practicing the Concepts of Decimals and PercentagesFrom EverandMath Practice Simplified: Decimals & Percents (Book H): Practicing the Concepts of Decimals and PercentagesRating: 5 out of 5 stars5/5 (3)
- Case Study On GynaeDocument22 pagesCase Study On GynaeJay PaulNo ratings yet
- The Beauty of DentistryDocument5 pagesThe Beauty of DentistryMorosanu Diana GeorgianaNo ratings yet
- The Five Level Model A New Approach To Organizing Body Composition ResearchDocument10 pagesThe Five Level Model A New Approach To Organizing Body Composition ResearchGabriel FagundesNo ratings yet
- CAIE Biology A-Level: Topic 10 - Infectious DiseasesDocument3 pagesCAIE Biology A-Level: Topic 10 - Infectious Diseasesstephen areriNo ratings yet
- Kuliayada CaafimaadkaDocument50 pagesKuliayada CaafimaadkaKhalid Abdiaziz AbdulleNo ratings yet
- 10 ĐỀ THI KSCL LẦN 2 NĂM HỌC 2021Document4 pages10 ĐỀ THI KSCL LẦN 2 NĂM HỌC 2021Sơn Cao ThanhNo ratings yet
- Early Intervention Support and Inclusion For Children With Disability - ADHCDocument4 pagesEarly Intervention Support and Inclusion For Children With Disability - ADHCMirolz PomenNo ratings yet
- List of Important World International DaysDocument32 pagesList of Important World International DaysYassir ButtNo ratings yet
- Ch10 - Critical Thinking and Clinical ReasoningDocument31 pagesCh10 - Critical Thinking and Clinical ReasoningVinz TombocNo ratings yet
- Paracetamol IV 10mg/ml 50ml 100ml Solution For Infusion PIL - UK BBBA6849Document2 pagesParacetamol IV 10mg/ml 50ml 100ml Solution For Infusion PIL - UK BBBA6849Ganesh NaniNo ratings yet
- OB Ward Case StudyDocument20 pagesOB Ward Case StudyIvan A. EleginoNo ratings yet
- Periodontal Accelerated Osteogenic OrthodonticsDocument6 pagesPeriodontal Accelerated Osteogenic Orthodonticsyui cherryNo ratings yet
- Additive EfectDocument8 pagesAdditive EfectMAIN FIRSTFLOORBNo ratings yet
- Transes Anaphy BloodDocument5 pagesTranses Anaphy BloodPia LouiseNo ratings yet
- NSTP Unit 4Document14 pagesNSTP Unit 4Sophie DatuNo ratings yet
- Micoses Superficiais - GlobalDocument19 pagesMicoses Superficiais - GlobalJosé Paulo Ribeiro JúniorNo ratings yet
- 05 23 12+Grad+Entire+IssueDocument48 pages05 23 12+Grad+Entire+IssueVivek SarthiNo ratings yet
- Latihan Abbreviation 2Document2 pagesLatihan Abbreviation 2Sherly AmeliaNo ratings yet
- Care of Orthopedic Patients With Baker CystsDocument27 pagesCare of Orthopedic Patients With Baker CystsLuayon FrancisNo ratings yet
- Salivaryglands 2 Cpalate 2 Cpharynx 2 CswallowingDocument11 pagesSalivaryglands 2 Cpalate 2 Cpharynx 2 Cswallowingr74k8zgg8rNo ratings yet
- MCU PACKAGE PTVI Contractor (Operational Area) SentDocument1 pageMCU PACKAGE PTVI Contractor (Operational Area) Sentmuh.hasbi asbukNo ratings yet
- Assessment of Knowledge Sharing For Prevention of Hepatitis Viral Infection Among Students of Higher Institutions of Kebbi State, NigeriaDocument9 pagesAssessment of Knowledge Sharing For Prevention of Hepatitis Viral Infection Among Students of Higher Institutions of Kebbi State, NigeriaInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Vaccine: Greg G. WolffDocument5 pagesVaccine: Greg G. WolffRennan Lima M. CastroNo ratings yet
- Head TraumaDocument22 pagesHead TraumaEllsay AliceNo ratings yet
- Reference ID: 4109856: 1 Indications and Usage 4 ContraindicationsDocument52 pagesReference ID: 4109856: 1 Indications and Usage 4 Contraindicationsgmsanto7No ratings yet
- Case Based Discussion: Sindy Helda PutriDocument30 pagesCase Based Discussion: Sindy Helda PutriSindyputri HeldaNo ratings yet