You might also like
- Pima Indian Diabetes QuestionsDocument6 pagesPima Indian Diabetes QuestionsAMAN PRAKASHNo ratings yet
- Pipe Stowage Plan SpreadsheetDocument10 pagesPipe Stowage Plan Spreadsheetilham saloNo ratings yet
- Queue Program in CDocument3 pagesQueue Program in Cمحمد جمالیNo ratings yet
- Homework 3Document1 pageHomework 3Sinta RahmawidyaNo ratings yet
- Diabetes Prediction SystemDocument4 pagesDiabetes Prediction Systemsaurabh khairnarNo ratings yet
- Healthcare PGP - Capstone ProjectDocument32 pagesHealthcare PGP - Capstone ProjectSneh Prakhar0% (1)
- Univariate and Multivariate Analysis - Jupyter NotebookDocument5 pagesUnivariate and Multivariate Analysis - Jupyter NotebookAnuvidyaKarthiNo ratings yet
- DAL Experiment Outputs 6to10Document16 pagesDAL Experiment Outputs 6to10sujaykulkarni755No ratings yet
- Healthcare PGPDocument28 pagesHealthcare PGPSneh PrakharNo ratings yet
- Step-By-Step-Diabetes-Classification-Knn-Detailed-Copy1 - Jupyter NotebookDocument12 pagesStep-By-Step-Diabetes-Classification-Knn-Detailed-Copy1 - Jupyter NotebookElyzaNo ratings yet
- Loading The Dataset: 'Diabetes - CSV'Document4 pagesLoading The Dataset: 'Diabetes - CSV'Divyani ChavanNo ratings yet
- Diabetes Diagrama de ArbolDocument4 pagesDiabetes Diagrama de ArbolRamón MendozaNo ratings yet
- Diabetes Diagrama de ArbolDocument4 pagesDiabetes Diagrama de ArbolRamón MendozaNo ratings yet
- SVM - RF - Diabetes - CSV - 26 - 6 - 2023.ipynb - ColaboratoryDocument8 pagesSVM - RF - Diabetes - CSV - 26 - 6 - 2023.ipynb - Colaboratoryutsavarora1912No ratings yet
- Capstone Project 2Document15 pagesCapstone Project 2DavidNo ratings yet
- Mean Vector and Correlation Matrix in R - Jupyter NotebookDocument7 pagesMean Vector and Correlation Matrix in R - Jupyter NotebookAnuvidyaKarthiNo ratings yet
- ML - Workshop - Day2 - Jupyter NotebookDocument15 pagesML - Workshop - Day2 - Jupyter NotebookAbhisingNo ratings yet
- Diabetes ModelDocument44 pagesDiabetes Modelsasda100% (1)
- Name: MANOGNA GV Email Id: Major Project: Diabetes Prediction Let's Import Required Libraries!Document4 pagesName: MANOGNA GV Email Id: Major Project: Diabetes Prediction Let's Import Required Libraries!Manogna GvNo ratings yet
- Experiment 4Document5 pagesExperiment 4Apurva PatilNo ratings yet
- Tues Jan 30thDocument2 pagesTues Jan 30thapi-396947836No ratings yet
- One RDocument3 pagesOne Rketan lakumNo ratings yet
- Diabetic Prediction Using LogicalRegressionDocument9 pagesDiabetic Prediction Using LogicalRegressionYagnesh VyasNo ratings yet
- Foodlog Date February 13 - Daily IntakeDocument1 pageFoodlog Date February 13 - Daily Intakeapi-732764034No ratings yet
- Foodlog Date 02 04 24Document1 pageFoodlog Date 02 04 24api-732738212No ratings yet
- To Extract Features From Given Data Set and Establish Training DataDocument2 pagesTo Extract Features From Given Data Set and Establish Training DataRAHUL DARANDALENo ratings yet
- Diabetis ProjectDocument7 pagesDiabetis ProjectKeerthi SankaraNo ratings yet
- Foodlog Day 1Document4 pagesFoodlog Day 1api-397125493No ratings yet
- Total Caloric Intake Daily ValueDocument3 pagesTotal Caloric Intake Daily Valueapi-541657234No ratings yet
- Kevin Soto Foodlog Date 2 9 - Daily Intake 1Document1 pageKevin Soto Foodlog Date 2 9 - Daily Intake 1api-732087714No ratings yet
- Foodlog Date February 12 - Daily IntakeDocument1 pageFoodlog Date February 12 - Daily Intakeapi-732764034No ratings yet
- Foodlog Date 2 3 22 - Daily IntakeDocument1 pageFoodlog Date 2 3 22 - Daily Intakeapi-593701830No ratings yet
- ML Practical 04Document20 pagesML Practical 04whitehouse2202No ratings yet
- Tuesday 1 2f30Document3 pagesTuesday 1 2f30api-396979246No ratings yet
- Jan 2f31Document2 pagesJan 2f31api-392591184No ratings yet
- Foodlog Date February 8 - Daily IntakeDocument1 pageFoodlog Date February 8 - Daily Intakeapi-732764034No ratings yet
- Foodlog Date Thurs 2 8 24 - Daily IntakeDocument1 pageFoodlog Date Thurs 2 8 24 - Daily Intakeapi-732536412No ratings yet
- Thur Feb 8Document3 pagesThur Feb 8api-398289109No ratings yet
- Foodlog Date 2 4 22 - Daily Intake-2Document1 pageFoodlog Date 2 4 22 - Daily Intake-2api-593701830No ratings yet
- Total Caloric Intake Daily ValueDocument3 pagesTotal Caloric Intake Daily Valueapi-541455506No ratings yet
- Saturday February 10Document2 pagesSaturday February 10api-396947836No ratings yet
- Foodlog Date Monday 01-31-22 - Daily IntakeDocument1 pageFoodlog Date Monday 01-31-22 - Daily Intakeapi-594235727No ratings yet
- Foodlog Date Monday January 30th 2023 - Daily Intake 1Document1 pageFoodlog Date Monday January 30th 2023 - Daily Intake 1api-655790273No ratings yet
- Thursday 2 2f1Document3 pagesThursday 2 2f1api-396979246No ratings yet
- Foodlog Date Mon 2 12 24 - Daily IntakeDocument1 pageFoodlog Date Mon 2 12 24 - Daily Intakeapi-732536412No ratings yet
- Mechelleg-Foodlog Date Sunday 2-11-24 - Daily IntakeDocument1 pageMechelleg-Foodlog Date Sunday 2-11-24 - Daily Intakeapi-732565843No ratings yet
- Total Caloric Intake Daily ValueDocument2 pagesTotal Caloric Intake Daily Valueapi-396948496No ratings yet
- Tuesday 2 2f6Document3 pagesTuesday 2 2f6api-396979246No ratings yet
- 1 2f31 2f18 FoodlogtemplateDocument4 pages1 2f31 2f18 Foodlogtemplateapi-397103331No ratings yet
- Foodlog Date 2 11 24 - Daily IntakeDocument1 pageFoodlog Date 2 11 24 - Daily Intakeapi-732045328No ratings yet
- Friday February 2ndDocument2 pagesFriday February 2ndapi-396947836No ratings yet
- Foodlog Date February 2 - Daily IntakeDocument1 pageFoodlog Date February 2 - Daily Intakeapi-732764034No ratings yet
- Monday 1 29 - Sheet1Document2 pagesMonday 1 29 - Sheet1api-397118630No ratings yet
- Copy of Foodlog Date FebDocument1 pageCopy of Foodlog Date Febapi-731840566No ratings yet
- Monday Feburary 5thDocument2 pagesMonday Feburary 5thapi-396947836No ratings yet
- Mon Feb 5Document3 pagesMon Feb 5api-398289109No ratings yet
- Foodlog Date February 14 - Daily IntakeDocument1 pageFoodlog Date February 14 - Daily Intakeapi-732764034No ratings yet
- Saturday 2 5 - Daily IntakeDocument1 pageSaturday 2 5 - Daily Intakeapi-595353195No ratings yet
- Saturday Feb10 1Document3 pagesSaturday Feb10 1api-397149898No ratings yet
- Order Symbol Name IPO Date Ind Group Rank Industry NameDocument6 pagesOrder Symbol Name IPO Date Ind Group Rank Industry NameLars BakerNo ratings yet
- Foodlog Date Thursday 2 3 2022 - Daily IntakeDocument1 pageFoodlog Date Thursday 2 3 2022 - Daily Intakeapi-593379162No ratings yet
- Total Caloric Intake Daily ValueDocument2 pagesTotal Caloric Intake Daily Valueapi-397133233No ratings yet
- Math Practice Simplified: Decimals & Percents (Book H): Practicing the Concepts of Decimals and PercentagesFrom EverandMath Practice Simplified: Decimals & Percents (Book H): Practicing the Concepts of Decimals and PercentagesRating: 5 out of 5 stars5/5 (3)
- P03 Confidence RegionDocument7 pagesP03 Confidence RegionYANDRAPU MANOJ NAIDU 20MDT1017No ratings yet
- MAT5010 - Foundations of Data Science: AssignmentDocument2 pagesMAT5010 - Foundations of Data Science: AssignmentYANDRAPU MANOJ NAIDU 20MDT1017No ratings yet
- The Calculation of Transmission Networks With The Aid of Graph TheoryDocument14 pagesThe Calculation of Transmission Networks With The Aid of Graph TheoryYANDRAPU MANOJ NAIDU 20MDT1017No ratings yet
- Mat5011 - Digital Assignment 2Document2 pagesMat5011 - Digital Assignment 2YANDRAPU MANOJ NAIDU 20MDT1017No ratings yet
- Lexical Syntax and Parsing: Session-27Document30 pagesLexical Syntax and Parsing: Session-27YANDRAPU MANOJ NAIDU 20MDT1017No ratings yet
- Unit-8: Advanced Microprocessor: (MPI) GTU # 3160712Document129 pagesUnit-8: Advanced Microprocessor: (MPI) GTU # 3160712GajjuNo ratings yet
- Lab Guides: Java SE 8 Programming LanguageDocument4 pagesLab Guides: Java SE 8 Programming LanguageLe DoanNo ratings yet
- Computing System ArchDocument5 pagesComputing System ArchAditya JadhavNo ratings yet
- Counting HWDocument10 pagesCounting HWsimo simaNo ratings yet
- 2nd Quarter Exam Math, TagazaDocument4 pages2nd Quarter Exam Math, TagazaAngelo Travis TagazaNo ratings yet
- Combinational Logic CircuitsDocument32 pagesCombinational Logic CircuitsShaikh Arham AyazNo ratings yet
- r20 I-II PWC++ Lab Manual 20ecl203 22-23Document27 pagesr20 I-II PWC++ Lab Manual 20ecl203 22-23anchapremNo ratings yet
- Beau Mount TalkDocument68 pagesBeau Mount TalkanazorNo ratings yet
- Multiple Choice Questions, COPA, Semester-2: Dr.V.NagaradjaneDocument115 pagesMultiple Choice Questions, COPA, Semester-2: Dr.V.NagaradjaneER Hariram PrajapatNo ratings yet
- Unit 2-Exercises - SolutionsDocument16 pagesUnit 2-Exercises - SolutionsAnita Sofia KeyserNo ratings yet
- Chomsky Normal Form: By: Aamina Bilqees Ramla Nigar Muniba Afzal Asma Ishtiaq Rimsha BasharatDocument16 pagesChomsky Normal Form: By: Aamina Bilqees Ramla Nigar Muniba Afzal Asma Ishtiaq Rimsha BasharatAmmara Younas 3831-FBAS/BSCS/F18No ratings yet
- D) All of The Above A) AVL TreeDocument26 pagesD) All of The Above A) AVL TreeAbhi BNo ratings yet
- Key Data Extraction and Emotion Analysis of Digital Shopping Based On BERTDocument14 pagesKey Data Extraction and Emotion Analysis of Digital Shopping Based On BERTsaRIKANo ratings yet
- WWW Studocu Com in N 29646569 Sid 01682568219Document1 pageWWW Studocu Com in N 29646569 Sid 01682568219Nivetha SelvamuruganNo ratings yet
- Anomaly Detection in Self-Organizing Networks - Conventional Versus Contemporary Machine LearningDocument9 pagesAnomaly Detection in Self-Organizing Networks - Conventional Versus Contemporary Machine LearningSudhakar HOD i/cNo ratings yet
- CSC 490Document5 pagesCSC 490ندى البلويNo ratings yet
- 01.2 PB Java First Steps in Coding LabDocument14 pages01.2 PB Java First Steps in Coding LabA AmraaNo ratings yet
- Python 2 Lab EsyDocument34 pagesPython 2 Lab EsySharukh HussainNo ratings yet
- Quiz - 05Document6 pagesQuiz - 05Demo Account 1No ratings yet
- X 64 DBGDocument283 pagesX 64 DBGFilmy StudioNo ratings yet
- Applied Questions - Sequences and SeriesDocument2 pagesApplied Questions - Sequences and SeriesMohamed LaamirNo ratings yet
- CSC 413 AssDocument7 pagesCSC 413 AssKc MamaNo ratings yet
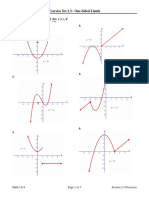
- Exercise Set 2.3: One-Sided Limits: FX, FX and FX, IfDocument3 pagesExercise Set 2.3: One-Sided Limits: FX, FX and FX, IfValentino Leo SaputraNo ratings yet
- De (Unit-1) (Practice Sheet) PsitcoeDocument5 pagesDe (Unit-1) (Practice Sheet) PsitcoeA's Was UnlikedNo ratings yet
- Artificial IntelligenceDocument41 pagesArtificial IntelligenceAakash ShresthaNo ratings yet
- Lecture 23: Memory Representation of Trees, Traversal AlgorithmsDocument4 pagesLecture 23: Memory Representation of Trees, Traversal AlgorithmsHimantika SharmaNo ratings yet
- CS311 Operating Systems: Hugh Anderson Maths and Computing Science, USP Anderson - H@usp - Ac.fjDocument130 pagesCS311 Operating Systems: Hugh Anderson Maths and Computing Science, USP Anderson - H@usp - Ac.fjAYA RACHEKNo ratings yet