You might also like
- SolutionsShumway PDFDocument82 pagesSolutionsShumway PDFjuve A.No ratings yet
- EN 571 Homework 5Document2 pagesEN 571 Homework 5kelsi chanNo ratings yet
- 02 ML Sol MidSem - Makeup - Sol - Upated (From Bits)Document6 pages02 ML Sol MidSem - Makeup - Sol - Upated (From Bits)sourab jainNo ratings yet
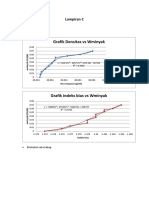
- Grafik Densitas Vs Wminyak: Lampiran CDocument9 pagesGrafik Densitas Vs Wminyak: Lampiran CYoel LavenkiNo ratings yet
- GraphDocument3 pagesGraphneeraj2811No ratings yet
- Grafik Hukum OhmDocument4 pagesGrafik Hukum Ohmnur insanaNo ratings yet
- Grafik Hukum OhmDocument4 pagesGrafik Hukum Ohmnur insanaNo ratings yet
- Tutorial 8 Markov Analysis SolutionDocument5 pagesTutorial 8 Markov Analysis SolutionJum Sheng ChongNo ratings yet
- SPH4U1 - Centripetal Lab ReportDocument14 pagesSPH4U1 - Centripetal Lab ReportVictoria MaziluNo ratings yet
- Least Square FilterDocument5 pagesLeast Square Filterduc2711No ratings yet
- ElastisitasDocument2 pagesElastisitasNabilah AinayahNo ratings yet
- Metodos NumericosejDocument6 pagesMetodos NumericosejLuis CastilloNo ratings yet
- Laporan Sementara Aplikasi Pitch Dan Formant: 1. Pencarian Frekuensi Fundamental Dengan Metode Auto KorelasiDocument13 pagesLaporan Sementara Aplikasi Pitch Dan Formant: 1. Pencarian Frekuensi Fundamental Dengan Metode Auto KorelasiFardhan ZabidNo ratings yet
- Amperimetro: Resistencia Equivalente (Ω)Document2 pagesAmperimetro: Resistencia Equivalente (Ω)williamNo ratings yet
- Student259: Plot of Concentration (MG/L) Vs Time (Min)Document6 pagesStudent259: Plot of Concentration (MG/L) Vs Time (Min)monarchNo ratings yet
- Design of Mat Foundation Mat Foundation Design (ACI 318-14) - MetricDocument15 pagesDesign of Mat Foundation Mat Foundation Design (ACI 318-14) - MetricjansenrosesNo ratings yet
- Mov en Una Dimension GraficasDocument4 pagesMov en Una Dimension GraficasDamarinaNo ratings yet
- Tabel As Ar Condicion A DoDocument60 pagesTabel As Ar Condicion A DoJanaynaNo ratings yet
- (TE208) Projeto 01 - Fortunato NetoDocument15 pages(TE208) Projeto 01 - Fortunato NetoFortunato NetoNo ratings yet
- 05 Modellingtutorial - 1storderresponses - NADocument2 pages05 Modellingtutorial - 1storderresponses - NAElie KabangaNo ratings yet
- Secondary Stage: Strain (ε)Document2 pagesSecondary Stage: Strain (ε)muchamad luthfi aliNo ratings yet
- Concentration Naoh Vs Conductivity: 2.0 ResultsDocument6 pagesConcentration Naoh Vs Conductivity: 2.0 ResultsnisasoberiNo ratings yet
- Chapter-5: Problem-3: X (# Leftover Units) ProbabilityDocument1 pageChapter-5: Problem-3: X (# Leftover Units) ProbabilityHarshal ShindeNo ratings yet
- Final Report Mohamed Alahmed and Ahmed Albusmait PDFDocument13 pagesFinal Report Mohamed Alahmed and Ahmed Albusmait PDFIbm4444No ratings yet
- Week 3 Homework Suggested SolutionDocument27 pagesWeek 3 Homework Suggested SolutionMr. JarmenNo ratings yet
- Teme FizicaaaDocument12 pagesTeme FizicaaaLarissa TomlinsonNo ratings yet
- ELEC 310: Microelectronic Circuits and Devices: LAB # 07: BJT Frequency ResponseDocument3 pagesELEC 310: Microelectronic Circuits and Devices: LAB # 07: BJT Frequency ResponseBerke KadıoğluNo ratings yet
- Task#1: Generate The Binomial Distribution With FollowingDocument6 pagesTask#1: Generate The Binomial Distribution With FollowingMuhammad NaveedNo ratings yet
- Assignment LabDocument2 pagesAssignment LabJames XgunNo ratings yet
- td1 2020 PDFDocument2 pagestd1 2020 PDFAZONTO conradNo ratings yet
- Enzyme DataDocument36 pagesEnzyme DataSamuel HastingsNo ratings yet
- Matchpredictor 2Document31 pagesMatchpredictor 2api-3805003No ratings yet
- 1.1 Step Response: Lab 2 - MECH 4310.002 Josiah Rohne Kingslea StringhamDocument8 pages1.1 Step Response: Lab 2 - MECH 4310.002 Josiah Rohne Kingslea StringhamChrisCaywoodNo ratings yet
- Hitungan Di Lab BahanDocument5 pagesHitungan Di Lab BahanvanilivaniliNo ratings yet
- Ficha Electrica Led Downlight 30wDocument3 pagesFicha Electrica Led Downlight 30wLuis Lujan ArevaloNo ratings yet
- Informe 8 PT1 y PT2Document7 pagesInforme 8 PT1 y PT2HUBER FERNANDO SUCASARA APAZANo ratings yet
- Julia Silviani: 0.025 0.03 F (X) 0.028x - 0.0006666667 R 0.9811680572 Column D Linear (Column D)Document3 pagesJulia Silviani: 0.025 0.03 F (X) 0.028x - 0.0006666667 R 0.9811680572 Column D Linear (Column D)efli pratama dinaNo ratings yet
- Chapter 5: Risk and Return: Portfolio Theory and Assets Pricing ModelsDocument3 pagesChapter 5: Risk and Return: Portfolio Theory and Assets Pricing ModelsMukul KadyanNo ratings yet
- Chemical Kinetics Simulator: An Interactive Graphical ApproachDocument8 pagesChemical Kinetics Simulator: An Interactive Graphical Approachnurul ismiNo ratings yet
- ResultsDocument6 pagesResultsNora ZuraNo ratings yet
- Kurva Turbidimetri AsliDocument2 pagesKurva Turbidimetri AsliCindy nurul FaradilaNo ratings yet
- 09-05 Power Curves - ExamplesDocument2 pages09-05 Power Curves - ExamplesThanh NganNo ratings yet
- Adc Lab 3Document6 pagesAdc Lab 3ahad mushtaqNo ratings yet
- Cyclic Simple Shear Test: Need and ScopeDocument14 pagesCyclic Simple Shear Test: Need and ScopeMAJIDNo ratings yet
- TP Charege R .SMVDocument1 pageTP Charege R .SMVBelkacem BouacherineNo ratings yet
- Discussion Batch SaponificationDocument4 pagesDiscussion Batch SaponificationSuria Seri SulyanaNo ratings yet
- Ficha Electrica Hermetico Led 40 W Mod IntegradoDocument3 pagesFicha Electrica Hermetico Led 40 W Mod IntegradoLuis Lujan ArevaloNo ratings yet
- q1 Probability 1Document5 pagesq1 Probability 1bihaNo ratings yet
- Exercise 5: Sieve Analysis (20 Points) : Cummulative Grain Size DistributionDocument1 pageExercise 5: Sieve Analysis (20 Points) : Cummulative Grain Size DistributionSakura ShirayukiNo ratings yet
- Lab 05Document6 pagesLab 05Mohsin IqbalNo ratings yet
- Absorbance at λmax 260nm for PBS: Calibration curvesDocument3 pagesAbsorbance at λmax 260nm for PBS: Calibration curvesNaveedNo ratings yet
- CHM3270 Ch12.1 Activity3 KEYDocument2 pagesCHM3270 Ch12.1 Activity3 KEYTaiNo ratings yet
- Maximum Likelihood Parameter Estimates Using Multiple Stripes Analysis Data Jack Baker July 15, 2011Document4 pagesMaximum Likelihood Parameter Estimates Using Multiple Stripes Analysis Data Jack Baker July 15, 2011Joseph772No ratings yet
- Graph of Fe (N) Vs FL (N)Document5 pagesGraph of Fe (N) Vs FL (N)anon_287779918No ratings yet
- Graphs MODocument9 pagesGraphs MOMANIKANDAN A SNo ratings yet
- Interaction Diagram Circular Column2Document10 pagesInteraction Diagram Circular Column2Diego DíazNo ratings yet
- Matchpredictor v1.41Document8 pagesMatchpredictor v1.41kajhejlesenNo ratings yet
- Fault StudyDocument12 pagesFault StudypasanhesharaNo ratings yet
- Error Analysis NotesDocument3 pagesError Analysis NotesNaysa RenjuNo ratings yet
- Vintage Knits For Modern Babies by Hadley Fierlinger - Wee Mittens ProjectDocument3 pagesVintage Knits For Modern Babies by Hadley Fierlinger - Wee Mittens ProjectCrafterNews20% (5)
- HANDOUT Family Planning ProgramDocument3 pagesHANDOUT Family Planning ProgramJannen CasasNo ratings yet
- DLL - All Subjects 2 - Q4 - W3 - D1Document8 pagesDLL - All Subjects 2 - Q4 - W3 - D1Lovely JazminNo ratings yet
- Mohammad Nasir UddinDocument2 pagesMohammad Nasir UddinMohammad Nasir UddinNo ratings yet
- Individual 1st GradingDocument18 pagesIndividual 1st GradingJep Jep PanghulanNo ratings yet
- PH and Buffer System - NotesDocument29 pagesPH and Buffer System - Noteskatherine morenoNo ratings yet
- SH ITAS 4 Dao-As and FortunatoDocument29 pagesSH ITAS 4 Dao-As and FortunatoAziil LiizaNo ratings yet
- Mcclelland's Three Need TheoryDocument16 pagesMcclelland's Three Need TheorySaurabh Sharma100% (1)
- CT HSRW PhysicsDocument2 pagesCT HSRW PhysicsEsther AtwineNo ratings yet
- Deutsch Für Deutsche KinderDocument9 pagesDeutsch Für Deutsche Kinderj7neyoNo ratings yet
- Preserving The Fading Traditional Art Forms in MalaysiaDocument20 pagesPreserving The Fading Traditional Art Forms in Malaysiaa31261192No ratings yet
- Entrep12 q1 m1 Introduction-To-EntrepreneurshipDocument20 pagesEntrep12 q1 m1 Introduction-To-EntrepreneurshipYvonne CafeNo ratings yet
- DocumentDocument3 pagesDocumentMichael ChinalpanNo ratings yet
- Subir Sesión InicialDocument13 pagesSubir Sesión InicialMARELSI NOEMI CASTAÑEDA MACHUCANo ratings yet
- My ResumeDocument2 pagesMy Resumeapi-548259305No ratings yet
- Name - No. - Class - Date - / - / - Mark - TeacherDocument4 pagesName - No. - Class - Date - / - / - Mark - TeacherAlexandra SoeiroNo ratings yet
- Contrastive Linguistics - Assignment 1 and 2Document15 pagesContrastive Linguistics - Assignment 1 and 2BadaraNo ratings yet
- Dance Critique PaperDocument3 pagesDance Critique Paperapi-243405519No ratings yet
- Mixed Level TeachingDocument14 pagesMixed Level TeachingTaraprasad PaudyalNo ratings yet
- How To Escape A False Growth Mindset: UniversityDocument23 pagesHow To Escape A False Growth Mindset: UniversityMirela Osman100% (2)
- Creating A Scheme of Work This Handout Will CoverDocument5 pagesCreating A Scheme of Work This Handout Will CoverErnest JacksonNo ratings yet
- The Fun They HadDocument16 pagesThe Fun They HadCami RodriguezNo ratings yet
- Strategies To Improve Memory and RetentionDocument5 pagesStrategies To Improve Memory and RetentionJose Anand Salvador LegaspiNo ratings yet
- Agreement PetronasDocument2 pagesAgreement PetronasMuhammad IdrisNo ratings yet
- 1.3 Learner-Centered TeachingDocument5 pages1.3 Learner-Centered TeachingMeenaSakthi100% (1)
- Past Simple and Past PerfectDocument15 pagesPast Simple and Past Perfectwill13877No ratings yet
- Nirmal BhaktiDocument3 pagesNirmal BhaktiSCSMathPhilippines1992No ratings yet
- 07 BibliographyDocument29 pages07 BibliographySem JeanNo ratings yet
- OperationswithdecimalsDocument8 pagesOperationswithdecimalsEdzel JosonNo ratings yet
- Implications of Vygotsky's Zone of Proximal Development (ZPD) in Teacher Education: ZPTD and Self-ScaffoldingDocument7 pagesImplications of Vygotsky's Zone of Proximal Development (ZPD) in Teacher Education: ZPTD and Self-ScaffoldingJenniffer Cortez TagleNo ratings yet