You might also like
- Statistics for the Teacher: Pergamon International Library of Science, Technology, Engineering and Social StudiesFrom EverandStatistics for the Teacher: Pergamon International Library of Science, Technology, Engineering and Social StudiesNo ratings yet
- Bes Project 2021Document15 pagesBes Project 2021Trịnh Huyền ThươngNo ratings yet
- Bes Project 2021Document15 pagesBes Project 2021Trịnh Huyền ThươngNo ratings yet
- Bes ReportDocument16 pagesBes ReportPhạm Phương AnhNo ratings yet
- Arts July 2016Document5 pagesArts July 2016Abderrahim LaitNo ratings yet
- Tracer Study NopradaQuiatchonTuyaySabaybayDocument36 pagesTracer Study NopradaQuiatchonTuyaySabaybayMa. Gemille NopradaNo ratings yet
- Examen Anglais Science Humaines 2018 Session Rattrapage SujetDocument8 pagesExamen Anglais Science Humaines 2018 Session Rattrapage SujetSoldier GoodNo ratings yet
- Mathematics: Quarter 3 - Module 2: Week 6 - Week 9Document41 pagesMathematics: Quarter 3 - Module 2: Week 6 - Week 9KARIZZA ABOLENCIANo ratings yet
- Revised Practical Research 2Document9 pagesRevised Practical Research 2storosariokitaotaobukidnonNo ratings yet
- 2021 7th Grade III Term Reinforcement WorksheetDocument3 pages2021 7th Grade III Term Reinforcement WorksheetAngie Alejandra León BallénNo ratings yet
- Presentation of Data: StatisticsDocument11 pagesPresentation of Data: StatisticsPetriena Alexis Clarke ForsytheNo ratings yet
- Lettter From Minister For Education Mr. John Watkins 24 February 2003Document2 pagesLettter From Minister For Education Mr. John Watkins 24 February 2003jolanda041No ratings yet
- 92statistics Annual92Document171 pages92statistics Annual92Abiy MulugetaNo ratings yet
- Nielsen Survey Form 1Document18 pagesNielsen Survey Form 1Enahj Conde DelmendoNo ratings yet
- Department of Education: Republic of The PhilippinesDocument6 pagesDepartment of Education: Republic of The PhilippinesMary Grace Delos SantosNo ratings yet
- The Reliability of The Educational Resources in de La Salle - College of Saint Benilde'S Learning Resource Center (LRC) For The Use of Shrim StudentsDocument20 pagesThe Reliability of The Educational Resources in de La Salle - College of Saint Benilde'S Learning Resource Center (LRC) For The Use of Shrim StudentsEmanuelLorbesNo ratings yet
- Admission Letter 2024 - Gianchere FinalDocument5 pagesAdmission Letter 2024 - Gianchere Finaldicksonkabichi0No ratings yet
- Final RequirementDocument8 pagesFinal RequirementDenmark CabadduNo ratings yet
- Esareiefacilitatorsguide.7Document2 pagesEsareiefacilitatorsguide.7Fred MednickNo ratings yet
- EL Middle SchoolsDocument37 pagesEL Middle SchoolsJerikho De JesusNo ratings yet
- Action Research JsteeleDocument60 pagesAction Research Jsteeleapi-240286998No ratings yet
- Diamond, Jefferies - 2001 - Beginning Statistics An Introduction For Social ScientistsDocument267 pagesDiamond, Jefferies - 2001 - Beginning Statistics An Introduction For Social ScientistsOscar ArsonistNo ratings yet
- Mathematics Activity Sheet Quarter 2 - MELC 1: Illustrating Situations That Involves VariationsDocument9 pagesMathematics Activity Sheet Quarter 2 - MELC 1: Illustrating Situations That Involves VariationsRohanisa TontoNo ratings yet
- Research On Satisfaction Level of Grade 11 Students Onthe CanteenDocument59 pagesResearch On Satisfaction Level of Grade 11 Students Onthe CanteenAile BogartNo ratings yet
- Foreign Trade University: Econometrics ReportDocument30 pagesForeign Trade University: Econometrics ReportNguyễn Quỳnh HươngNo ratings yet
- MathDocument21 pagesMathrkNo ratings yet
- Linggo NG Kabataan 2021 Project Proposal/ Activity DesignDocument3 pagesLinggo NG Kabataan 2021 Project Proposal/ Activity DesignMichael John Boragay100% (1)
- Hyde Park Central School District: Enrollment and Capacity StudyDocument68 pagesHyde Park Central School District: Enrollment and Capacity Studyapi-107641637No ratings yet
- Pennsylvania PromiseDocument27 pagesPennsylvania PromiseLancasterOnlineNo ratings yet
- Advanced StatsDocument32 pagesAdvanced StatsSai Saamrudh SaiganeshNo ratings yet
- Xi Holidays HomeworkDocument56 pagesXi Holidays HomeworkTarush GuptaNo ratings yet
- Midterm Exam First Semester 2017/2018Document7 pagesMidterm Exam First Semester 2017/2018reviandiramadhanNo ratings yet
- DM 391, S. 2021-Outstanding SBFP ImplementerDocument8 pagesDM 391, S. 2021-Outstanding SBFP ImplementerTholitzDatorNo ratings yet
- Econometrics IIDocument101 pagesEconometrics IIDENEKEW LESEMI100% (1)
- Debra NatashaDocument13 pagesDebra NatashaMAKCOM CENTRENo ratings yet
- Answer 1Document4 pagesAnswer 1Bhawna TiwariNo ratings yet
- Student Impact Project 11-25Document89 pagesStudent Impact Project 11-25api-299084383No ratings yet
- In Partial Fulfillment of The Requirements in MathDocument4 pagesIn Partial Fulfillment of The Requirements in MathDixie NormousNo ratings yet
- Name of Student: Course: Subject: Professorial LecturerDocument5 pagesName of Student: Course: Subject: Professorial LecturerGrace Mary JaoNo ratings yet
- Bucal National High School-ShsDocument21 pagesBucal National High School-ShsJohn Carlo Colipat80% (5)
- Examining The Relationship Between The Extracurricular Activities and Academic A 1 Finalllll 2Document20 pagesExamining The Relationship Between The Extracurricular Activities and Academic A 1 Finalllll 2g6mh4tsss7No ratings yet
- Kenya Relief Grant ProposalDocument31 pagesKenya Relief Grant ProposalgyrichardNo ratings yet
- Activity Sheets: Solving Problems Involving Test of Hypothesis On The Population MeanDocument7 pagesActivity Sheets: Solving Problems Involving Test of Hypothesis On The Population Meandthdtrh100% (2)
- Mathematics 9 LAS Quarter 3Document91 pagesMathematics 9 LAS Quarter 3Jake Padua94% (33)
- East Africa Report 2015Document36 pagesEast Africa Report 2015Gaudence KapingaNo ratings yet
- Chapter IIIDocument7 pagesChapter IIIKimberly Dulnuan PuguonNo ratings yet
- Activity Sheets: Quarter 3 - MELC 20Document10 pagesActivity Sheets: Quarter 3 - MELC 20BertiaNo ratings yet
- School Readiness Assessment 2012: June 2013Document92 pagesSchool Readiness Assessment 2012: June 2013Byaktiranjan PattanayakNo ratings yet
- Effects of Child LabourDocument30 pagesEffects of Child Labourcaroprinters01No ratings yet
- Feasibility-Study-2024-2025 SampleDocument8 pagesFeasibility-Study-2024-2025 Samplehnmjtw9kgsNo ratings yet
- Cicilia Mukonyo MutuaDocument9 pagesCicilia Mukonyo MutuaKelvinNo ratings yet
- Senior High School Canteen and Food Stall Outside The Campus Edited FinalDocument48 pagesSenior High School Canteen and Food Stall Outside The Campus Edited FinalZannie100% (4)
- ED 2019 ICCD 0148 0014 - Attachment - 1Document18 pagesED 2019 ICCD 0148 0014 - Attachment - 1Ramil ManlunasNo ratings yet
- Student Handbook 2008-2009Document12 pagesStudent Handbook 2008-2009atrombleNo ratings yet
- PreliminariesDocument10 pagesPreliminariesJulie Ann BagamaspadNo ratings yet
- TPS Newsletter - 12th June, 2014Document8 pagesTPS Newsletter - 12th June, 2014Romano StuderNo ratings yet
- LP Chapter 4 Lesson 3 Confidence Interval Estimate of The Population MeanDocument2 pagesLP Chapter 4 Lesson 3 Confidence Interval Estimate of The Population MeanAldrin Dela CruzNo ratings yet
- ExemplarDocument6 pagesExemplarNiesa CulturaNo ratings yet
- Chapter 3Document8 pagesChapter 3Jomelyn DawiNo ratings yet
- People With University Education Should Get Higher PayDocument1 pagePeople With University Education Should Get Higher PayTrịnh Huyền ThươngNo ratings yet
- The Business Performance of Consended-Milk From Dutch LadyDocument7 pagesThe Business Performance of Consended-Milk From Dutch LadyTrịnh Huyền ThươngNo ratings yet
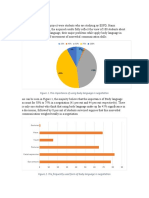
- Result: Figure 1. The Importance of Using Body Language in NegotiationDocument4 pagesResult: Figure 1. The Importance of Using Body Language in NegotiationTrịnh Huyền ThươngNo ratings yet
- Body Language in NegotiationDocument19 pagesBody Language in NegotiationTrịnh Huyền ThươngNo ratings yet
- PurposeDocument1 pagePurposeTrịnh Huyền ThươngNo ratings yet
- The Benefit and The Impact of MnemonicsDocument1 pageThe Benefit and The Impact of MnemonicsTrịnh Huyền ThươngNo ratings yet
- Lecture 1: Course Introduction, Review and Paired-Samples T-TestDocument13 pagesLecture 1: Course Introduction, Review and Paired-Samples T-TestTrịnh Huyền ThươngNo ratings yet
- Macro Tut 1Document6 pagesMacro Tut 1TACN-2M-19ACN Luu Khanh LinhNo ratings yet
- Macro Tut 1Document6 pagesMacro Tut 1TACN-2M-19ACN Luu Khanh LinhNo ratings yet
- Lec 1-Chapter 1 IntroDocument29 pagesLec 1-Chapter 1 IntroTrịnh Huyền ThươngNo ratings yet
- Who Is A Leader?Document14 pagesWho Is A Leader?Trịnh Huyền ThươngNo ratings yet
- What Do I Need To Know?: Chapter 2 Chapter 2Document8 pagesWhat Do I Need To Know?: Chapter 2 Chapter 2Trịnh Huyền ThươngNo ratings yet
- DIY Toolkit Arabic Web VersionDocument168 pagesDIY Toolkit Arabic Web VersionAyda AlshamsiNo ratings yet
- TCGRX BullsEye Tablet SplitterDocument2 pagesTCGRX BullsEye Tablet SplittermalucNo ratings yet
- Nursing Assessment in Family Nursing PracticeDocument22 pagesNursing Assessment in Family Nursing PracticeHydra Olivar - PantilganNo ratings yet
- 835 (Health Care Claim PaymentAdvice) - HIPAA TR3 GuideDocument306 pages835 (Health Care Claim PaymentAdvice) - HIPAA TR3 Guideअरूण शर्माNo ratings yet
- Effects of Corneal Scars and Their Treatment With Rigid Contact Lenses On Quality of VisionDocument5 pagesEffects of Corneal Scars and Their Treatment With Rigid Contact Lenses On Quality of VisionJasmine EffendiNo ratings yet
- Bearing 1Document27 pagesBearing 1desalegn hailemichaelNo ratings yet
- Review Course 2 (Review On Professional Education Courses)Document8 pagesReview Course 2 (Review On Professional Education Courses)Regie MarcosNo ratings yet
- DOT RequirementsDocument372 pagesDOT RequirementsMuhammadShabbirNo ratings yet
- Charter of The New UrbanismDocument4 pagesCharter of The New UrbanismBarabas SandraNo ratings yet
- Arc Hydro - Identifying and Managing SinksDocument35 pagesArc Hydro - Identifying and Managing SinkskbalNo ratings yet
- Turner Et Al. 1991 ASUDS SystemDocument10 pagesTurner Et Al. 1991 ASUDS SystemRocio HerreraNo ratings yet
- WD Support Warranty Services Business Return Material Authorization RMA Pre Mailer For ResellerDocument3 pagesWD Support Warranty Services Business Return Material Authorization RMA Pre Mailer For ResellerZowl SaidinNo ratings yet
- RESEARCHDocument5 pagesRESEARCHroseve cabalunaNo ratings yet
- Dummy 13 Printable Jointed Figure Beta FilesDocument9 pagesDummy 13 Printable Jointed Figure Beta FilesArturo GuzmanNo ratings yet
- Lab 1Document51 pagesLab 1aliNo ratings yet
- Periodic Table Lab AnswersDocument3 pagesPeriodic Table Lab AnswersIdan LevyNo ratings yet
- Bhavesh ProjectDocument14 pagesBhavesh ProjectRahul LimbaniNo ratings yet
- Immobilization of Rhodococcus Rhodochrous BX2 (An AcetonitriledegradingDocument7 pagesImmobilization of Rhodococcus Rhodochrous BX2 (An AcetonitriledegradingSahar IrankhahNo ratings yet
- Using Your Digital Assets On Q-GlobalDocument3 pagesUsing Your Digital Assets On Q-GlobalRemik BuczekNo ratings yet
- Nationalism, Feminism, and Modernity in PalestineDocument26 pagesNationalism, Feminism, and Modernity in PalestinebobandjoerockNo ratings yet
- Week 1 Familiarize The VmgoDocument10 pagesWeek 1 Familiarize The VmgoHizzel De CastroNo ratings yet
- MC4 CoCU 6 - Welding Records and Report DocumentationDocument8 pagesMC4 CoCU 6 - Welding Records and Report Documentationnizam1372100% (1)
- Uniden PowerMax 5.8Ghz-DSS5865 - 5855 User Manual PDFDocument64 pagesUniden PowerMax 5.8Ghz-DSS5865 - 5855 User Manual PDFtradosevic4091No ratings yet
- On The Wings of EcstasyDocument79 pagesOn The Wings of Ecstasygaya3mageshNo ratings yet
- P D P: C I D, C M: Design of Coastal RoadsDocument55 pagesP D P: C I D, C M: Design of Coastal RoadsMohammedNo ratings yet
- PedagogicalDocument94 pagesPedagogicalEdson MorenoNo ratings yet
- Half Yearly Examination, 2017-18: MathematicsDocument7 pagesHalf Yearly Examination, 2017-18: MathematicsSusanket DuttaNo ratings yet
- Effective TeachingDocument94 pagesEffective Teaching小曼No ratings yet
- Zillah P. Curato: ObjectiveDocument1 pageZillah P. Curato: ObjectiveZillah CuratoNo ratings yet
- CHAPTER I Lesson II Seven Environmental PrinciplesDocument17 pagesCHAPTER I Lesson II Seven Environmental PrinciplesTrixie jade DumotNo ratings yet