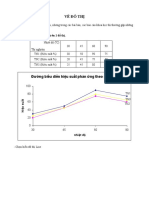
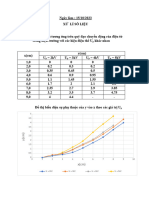
You might also like
- Hoi Quy Voi Du Lieu BangDocument127 pagesHoi Quy Voi Du Lieu BangNguyễn Quang Huy100% (1)
- phần 34Document2 pagesphần 34Di AnNo ratings yet
- Data Du Bao VeNhaDocument9 pagesData Du Bao VeNha34. Trần Thị Kim ThoaNo ratings yet
- Data Du Bao VeNhaDocument10 pagesData Du Bao VeNhathaole871No ratings yet
- Bai Tap Khoa Hoc Du LieuDocument6 pagesBai Tap Khoa Hoc Du LieuAnh NguyễnNo ratings yet
- Sử Dụng Mô Hình Arima Trong Dự Báo Giá Gạo Xuất Khẩu Của Việt NamDocument8 pagesSử Dụng Mô Hình Arima Trong Dự Báo Giá Gạo Xuất Khẩu Của Việt NamPhượng HuỳnhNo ratings yet
- Đặng Thị Hiền- BD001Document30 pagesĐặng Thị Hiền- BD001Khánh Vân TrầnNo ratings yet
- Data ScienceDocument7 pagesData ScienceThiều Yến NhiNo ratings yet
- XLSLBai 2Document5 pagesXLSLBai 2nguyentunganht65No ratings yet
- Bài tập lớn kinh tế lượng nhóm12Document10 pagesBài tập lớn kinh tế lượng nhóm12Thái Văn NgọcNo ratings yet
- Data - Du Bao - VeNhaDocument8 pagesData - Du Bao - VeNhacnhatduy2k5No ratings yet
- Nguyễn Phúc Minh Như Bài tập thực hành excel 1Document7 pagesNguyễn Phúc Minh Như Bài tập thực hành excel 1Trương Duy Bảo Nghĩa100% (1)
- NguyenThanhHieu Module6 BTDocument27 pagesNguyenThanhHieu Module6 BThieunt0471No ratings yet
- Hdan Kiểm Định Độ Tin Cậy Và Giá Trị Thang ĐoDocument6 pagesHdan Kiểm Định Độ Tin Cậy Và Giá Trị Thang ĐoNguyễn Bích NgọcNo ratings yet
- BTL LCN S ADocument8 pagesBTL LCN S AThái Đoàn MinhNo ratings yet
- THVL2 ĐỗTrọngTrúc-xl9Document6 pagesTHVL2 ĐỗTrọngTrúc-xl9dotrongtruct65No ratings yet
- Bài Làm SpssDocument37 pagesBài Làm SpssTrần Phương LanNo ratings yet
- Bài 2Document19 pagesBài 2huyenchu.31221027130No ratings yet
- Báo Cáo Thí Nghiệm Lý Thuyết Trường: Bài 1:Giải Phương Trình Poisson Và Phương Trình Laplace Dạng Sai Phân Bằng MatlabDocument7 pagesBáo Cáo Thí Nghiệm Lý Thuyết Trường: Bài 1:Giải Phương Trình Poisson Và Phương Trình Laplace Dạng Sai Phân Bằng Matlabapi-3798216No ratings yet
- Baitap ExcelDocument9 pagesBaitap ExcelThùy VânNo ratings yet
- Trade QuyDocument10 pagesTrade QuyLam Vi TuanNo ratings yet
- WLL Wire Rope Sling Per EN 13414-1Document1 pageWLL Wire Rope Sling Per EN 13414-1FOVIVA VNo ratings yet
- WLL Wire Rope Sling Per EN 13414-1Document1 pageWLL Wire Rope Sling Per EN 13414-1Nhien ManNo ratings yet
- thống kê ứng dụngDocument134 pagesthống kê ứng dụng21125620No ratings yet
- Bài Số 3 - Tiểu Nhóm 1 - Nhóm 4Document4 pagesBài Số 3 - Tiểu Nhóm 1 - Nhóm 4PHẠM VIỆT QUYÊNNo ratings yet
- BÀI TẬP DỰ BÁO.Document8 pagesBÀI TẬP DỰ BÁO.Trần Văn KỉNo ratings yet
- TKUD Nhóm 9Document6 pagesTKUD Nhóm 9Phuc HoangNo ratings yet
- 5 Dang MRBDocument21 pages5 Dang MRB22125327No ratings yet
- CH 5Document62 pagesCH 5Quân PhạmNo ratings yet
- Risk ResponsiblityDocument6 pagesRisk Responsiblitydtq1953401010044No ratings yet
- Bài Tập Lớn Môn: Kinh Tế Lượng: Nghiên cứu các nhân tố ảnh hưởng đến Tổng sản phẩm quốc nội của Việt Nam từ năm 1995-2011Document11 pagesBài Tập Lớn Môn: Kinh Tế Lượng: Nghiên cứu các nhân tố ảnh hưởng đến Tổng sản phẩm quốc nội của Việt Nam từ năm 1995-2011Như QuỳnhNo ratings yet
- BÁO CÁO TN NHÓMmDocument6 pagesBÁO CÁO TN NHÓMmTrực Hồ MinhNo ratings yet
- Các Mô Hình Tài ChínhDocument70 pagesCác Mô Hình Tài Chínhhk52ncwskcNo ratings yet
- BAI8Document7 pagesBAI8Đinh Đức ThànhNo ratings yet
- Bai Kiem Tra Ke Toan 63Document17 pagesBai Kiem Tra Ke Toan 63Linh LêNo ratings yet
- (123doc) Huong Dan Chay Mo Hinh Ols Fem Rem Tren Stata Lam Luan Van Thac Si Kem File Excel Du LieuDocument15 pages(123doc) Huong Dan Chay Mo Hinh Ols Fem Rem Tren Stata Lam Luan Van Thac Si Kem File Excel Du LieuTrangNo ratings yet
- Nguyễn Nam Khánh - 20202791Document9 pagesNguyễn Nam Khánh - 20202791Nguyễn Nam KhánhNo ratings yet
- Nguyễn Phước Dư - BT Tỷ giá hối đoáiDocument5 pagesNguyễn Phước Dư - BT Tỷ giá hối đoáinnguyenbao400No ratings yet
- Chap 4 KhoaDocument33 pagesChap 4 KhoaHUAN NGUYEN KHOANo ratings yet
- Tin - 10 - THPT CuMgarDocument6 pagesTin - 10 - THPT CuMgarti.dat2412No ratings yet
- Nguyễn Thị Thảo Trang-31221021691Document7 pagesNguyễn Thị Thảo Trang-31221021691Nguyễn Thị Thảo TrangNo ratings yet
- Bai Tap Chuong 11 - Phan Tich Bien Dong Chi Phi PDFDocument4 pagesBai Tap Chuong 11 - Phan Tich Bien Dong Chi Phi PDFChi HoàngNo ratings yet
- Ma - Acca - Du BaoDocument12 pagesMa - Acca - Du Baoloan thuỳNo ratings yet
- HoaptDocument4 pagesHoaptĐỗ Quang MinhNo ratings yet
- Cac BANG PHU LUCDocument4 pagesCac BANG PHU LUCntha290602No ratings yet
- KTHP PTDLDocument12 pagesKTHP PTDLVân Danh Thị ThuNo ratings yet
- Bài tập ứng dụng 1: Lập dự báo số lượng máy phát điện hiệu Honda của cửa hàng cơDocument17 pagesBài tập ứng dụng 1: Lập dự báo số lượng máy phát điện hiệu Honda của cửa hàng cơMinh Hải Trần DươngNo ratings yet
- Thủy Phân Ester Bằng Phương Pháp Đo Độ Dẫn: Họ tên các thành viên trong nhómDocument5 pagesThủy Phân Ester Bằng Phương Pháp Đo Độ Dẫn: Họ tên các thành viên trong nhómMinh Hiếu CaoNo ratings yet
- Bai 3 XuliDocument6 pagesBai 3 XuliQuốc AnhNo ratings yet
- Báo Cáo Hoá Phân Tích 2 - Bài 24Document6 pagesBáo Cáo Hoá Phân Tích 2 - Bài 24phamnhijb25No ratings yet
- (123doc) - Cac-Yeu-To-Anh-Huong-Den-Diem-Trung-Binh-Hoc-Tap-Cua-Sinh-VienDocument12 pages(123doc) - Cac-Yeu-To-Anh-Huong-Den-Diem-Trung-Binh-Hoc-Tap-Cua-Sinh-VienHuy NguyễnNo ratings yet
- Báo cáo thí nghiệm buổi 4- CSĐKTĐDocument13 pagesBáo cáo thí nghiệm buổi 4- CSĐKTĐquan minhNo ratings yet
- BT Tự HọcDocument8 pagesBT Tự Họctuanhnguyenthi766No ratings yet
- 125031 - Lê Văn Thuấn - 20196889 - Bài 1Document15 pages125031 - Lê Văn Thuấn - 20196889 - Bài 1Đức ChungNo ratings yet
- HHV1Document14 pagesHHV1Anh NguyễnNo ratings yet
- Bài tập buổi 2 KHDLDocument10 pagesBài tập buổi 2 KHDLThiều Yến NhiNo ratings yet
- Cơ Học Đất - Móng NôngDocument8 pagesCơ Học Đất - Móng NôngNguyễn Phước TrungNo ratings yet
- Bài số 2 - Tiểu nhóm 1 - Nhóm 4Document3 pagesBài số 2 - Tiểu nhóm 1 - Nhóm 4PHẠM VIỆT QUYÊNNo ratings yet
- KTQT Buổi.07 Luyện Tập Đáp-án-tham-khảo BHT.T3Document9 pagesKTQT Buổi.07 Luyện Tập Đáp-án-tham-khảo BHT.T3Ngọc ÁnhNo ratings yet