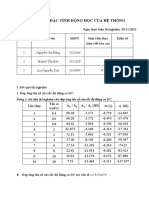
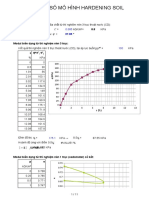
You might also like
- Bài 2 Điều Khiển Áp SuấtDocument2 pagesBài 2 Điều Khiển Áp SuấtThạch LươngNo ratings yet
- Báo Cáo Thí Nghiệm Cơ Sở Điều Khiển & Tự ĐộngDocument73 pagesBáo Cáo Thí Nghiệm Cơ Sở Điều Khiển & Tự ĐộngKhang NguyenNo ratings yet
- Báo cáo bài thí nghiệm 3Document28 pagesBáo cáo bài thí nghiệm 3Đô ĐôNo ratings yet
- BttonghopDocument7 pagesBttonghoptrucnguyen190203No ratings yet
- Bài 1,2 Báo CáoDocument106 pagesBài 1,2 Báo Cáobothm123456789No ratings yet
- Bài 1prelabcstdDocument9 pagesBài 1prelabcstdQuốc DoanhNo ratings yet
- Báo Cáo CSĐKTĐDocument39 pagesBáo Cáo CSĐKTĐDuy Lại NguyễnNo ratings yet
- Báo Cáo CSĐKTĐDocument20 pagesBáo Cáo CSĐKTĐPhùng AnNo ratings yet
- KTHP PTDLDocument12 pagesKTHP PTDLVân Danh Thị ThuNo ratings yet
- BAOCAOLAB2Document43 pagesBAOCAOLAB2khanguyenthanh27No ratings yet
- BaoCao TTDL Bai5Document3 pagesBaoCao TTDL Bai5thao.23y0306No ratings yet
- Chương 6. Vấn đề mở rộngDocument15 pagesChương 6. Vấn đề mở rộngHoài PhươngNo ratings yet
- Bao Cao DKNCDocument68 pagesBao Cao DKNCNam Huỳnh100% (1)
- SCT CocDocument6 pagesSCT Cocthuyetnt.lebruderNo ratings yet
- De Thi Them CLC - vo8esJtcNibfKFGKQ OriginalDocument10 pagesDe Thi Them CLC - vo8esJtcNibfKFGKQ OriginalPhương ThảoNo ratings yet
- Báo Cáo Bài 6 HTDKDocument24 pagesBáo Cáo Bài 6 HTDKhuy thanhNo ratings yet
- L07 04 Lab 2Document30 pagesL07 04 Lab 2Hào LữNo ratings yet
- CodeDocument27 pagesCodeNguyễn Tiến DũngNo ratings yet
- BT - KTL Chương 2Document5 pagesBT - KTL Chương 2Nguyen Thi Tuong ViNo ratings yet
- Báo Cáo Lab 2 T 1 l22Document36 pagesBáo Cáo Lab 2 T 1 l22caohieu882001No ratings yet
- Luyen Tap Cuoi Ky 1Document5 pagesLuyen Tap Cuoi Ky 1nganle.191004No ratings yet
- Bảng 1Document5 pagesBảng 1arsenal hieuNo ratings yet
- Hướng dẫn LTspice PDFDocument32 pagesHướng dẫn LTspice PDFNgọc ThiệnNo ratings yet
- ĐỀ THI KTLDocument6 pagesĐỀ THI KTLhoang191010No ratings yet
- Lab2 1Document7 pagesLab2 1khanh.truong170No ratings yet
- Nguyễn Hoàng Ân 20151097Document22 pagesNguyễn Hoàng Ân 20151097Dang Thanh HuyNo ratings yet
- 01.boost PHTTDocument28 pages01.boost PHTTpm0412222No ratings yet
- Huongdan StataDocument14 pagesHuongdan StataAn TuanNo ratings yet
- TH C HànhDocument24 pagesTH C HànhHoàng Thị ThùyNo ratings yet
- Báo cáo Bài TN3 - phần 1 - Nhóm 10 - Sinh vienDocument27 pagesBáo cáo Bài TN3 - phần 1 - Nhóm 10 - Sinh vienThành Cao ĐứcNo ratings yet
- VXL Baocao - Lab2 - 1Document21 pagesVXL Baocao - Lab2 - 1anhngoc.cgt.2012No ratings yet
- bài tập thực hành 2 (1) KTLDocument7 pagesbài tập thực hành 2 (1) KTLLamhymc123No ratings yet
- Bai 1 ĐKTĐDocument14 pagesBai 1 ĐKTĐDuy Lại NguyễnNo ratings yet
- Câu 1,2Document3 pagesCâu 1,2truonggiang27052004No ratings yet
- Chuong 3. Hoiquyboi - suydienTKDocument8 pagesChuong 3. Hoiquyboi - suydienTKHoài PhươngNo ratings yet
- (BTL-L03) N03 - DT3Document37 pages(BTL-L03) N03 - DT3Đoàn QuânNo ratings yet
- L02 Nhom05 2115167 2111923 2111529 Prelab2Document43 pagesL02 Nhom05 2115167 2111923 2111529 Prelab2Ngoc TuanNo ratings yet
- TNTTVT Bu I2 PH M Thành An 20187114Document22 pagesTNTTVT Bu I2 PH M Thành An 20187114An PhạmNo ratings yet
- Đ Án TKM in 9t5Document24 pagesĐ Án TKM in 9t5Văn LongNo ratings yet
- Hướng Dẫn sử dụng LTspiceDocument32 pagesHướng Dẫn sử dụng LTspiceMinh NgọcNo ratings yet
- HD Khai Thác TK BT XíchDocument21 pagesHD Khai Thác TK BT Xíchmạnh nguyễnNo ratings yet
- 1STT34 HÀ THỊ THÚY NGA KTLUD NGÀNH TÀI CHÍNH -NGÂN HÀNG D03 0338123845Document47 pages1STT34 HÀ THỊ THÚY NGA KTLUD NGÀNH TÀI CHÍNH -NGÂN HÀNG D03 0338123845Bắc Hà100% (1)
- Phân TíchDocument7 pagesPhân TíchNguyễn Thị MaiNo ratings yet
- BÁO CÁO TH C HÀNH Kit Moi NhatDocument32 pagesBÁO CÁO TH C HÀNH Kit Moi NhatĐức Nguyễn NgọcNo ratings yet
- Đặng Thị Hiền- BD001Document30 pagesĐặng Thị Hiền- BD001Khánh Vân TrầnNo ratings yet
- Bao Cao Nhan Dien Van TayDocument20 pagesBao Cao Nhan Dien Van Tayuyen01httNo ratings yet
- S A VÍ D KTLDocument16 pagesS A VÍ D KTLHao Tran ThiNo ratings yet
- Bài TH C Hành 7.1-Nhóm 6-L P 2Document6 pagesBài TH C Hành 7.1-Nhóm 6-L P 2tranthaonguyen040127No ratings yet
- Cơ Học Đất - Móng NôngDocument8 pagesCơ Học Đất - Móng NôngNguyễn Phước TrungNo ratings yet
- LAB4Document48 pagesLAB4Duy Vo100% (1)
- BT - KTL Chương 2 - 1Document5 pagesBT - KTL Chương 2 - 1Quang Khải ĐinhNo ratings yet
- BT - KTL Chương 2Document5 pagesBT - KTL Chương 2Quang Khải ĐinhNo ratings yet
- thinghiemTTVT SinhDocument18 pagesthinghiemTTVT SinhPhạm Thị Thu SinhNo ratings yet
- TN2# - L05 - Nhóm 2Document39 pagesTN2# - L05 - Nhóm 2Duy VoNo ratings yet
- L08 Nhóm01Document27 pagesL08 Nhóm01quynh.dinhtin847451No ratings yet
- Thong So HS ModelDocument11 pagesThong So HS ModelNam NguyenNo ratings yet
- Kinhteluongnhom 5Document8 pagesKinhteluongnhom 5myhoai036No ratings yet
- Hướng Dẫn Bài Tập Tkhtđ.1Document54 pagesHướng Dẫn Bài Tập Tkhtđ.122842179No ratings yet
- Ôn Thi Lư NGDocument4 pagesÔn Thi Lư NGNguyễn QuỳnhNo ratings yet
- C6-CSKTD - May Dien Khong Dong Bo - 3 - 6sDocument21 pagesC6-CSKTD - May Dien Khong Dong Bo - 3 - 6sThiện HàNo ratings yet
- Đề BTL XSTK HK193 - Đề số 1Document3 pagesĐề BTL XSTK HK193 - Đề số 1Thiện HàNo ratings yet
- BTL XSTKDocument14 pagesBTL XSTKThiện HàNo ratings yet
- Atd A05 03 BTLDocument9 pagesAtd A05 03 BTLThiện HàNo ratings yet
- C2 - Phan - 3Document21 pagesC2 - Phan - 3Thiện HàNo ratings yet
- Relab 5Document4 pagesRelab 5Thiện HàNo ratings yet
- BTL XSTK NG Kieu Dung DT03 Group2Document42 pagesBTL XSTK NG Kieu Dung DT03 Group2Thiện HàNo ratings yet