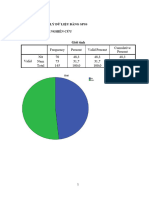
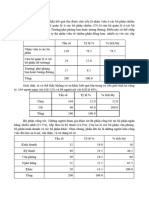
You might also like
- Chuong 8b - Phan Tich Cronbach AlphaDocument11 pagesChuong 8b - Phan Tich Cronbach Alphanamtp21No ratings yet
- Buổi 4 Kiểm Định Cronbach's AlphaDocument3 pagesBuổi 4 Kiểm Định Cronbach's AlphaTâm Phan Thị ThảoNo ratings yet
- Bai Kiem Tra 2 KTL HK1 2020Document2 pagesBai Kiem Tra 2 KTL HK1 2020Võ Thị Mỹ LanNo ratings yet
- Hdan Kiểm Định Độ Tin Cậy Và Giá Trị Thang ĐoDocument6 pagesHdan Kiểm Định Độ Tin Cậy Và Giá Trị Thang ĐoNguyễn Bích NgọcNo ratings yet
- SPSS HNDocument23 pagesSPSS HNHải Nam VũNo ratings yet
- Lương Nguyễn Kim ÁnhDocument10 pagesLương Nguyễn Kim Ánh02 Kim Ánh Lương NguyễnNo ratings yet
- Bài Tập PTDL Định KỳDocument8 pagesBài Tập PTDL Định Kỳtieuthitram9aNo ratings yet
- Báo cáo xác suất tkDocument65 pagesBáo cáo xác suất tkVÂN LÊ THUỲNo ratings yet
- Mau-Phan Tich Cronbach's AlphaDocument8 pagesMau-Phan Tich Cronbach's Alphanamtp21No ratings yet
- Phân Tích EFADocument4 pagesPhân Tích EFAsammm liflowmj.No ratings yet
- Testing The Reliability of The Measures CronbachDocument28 pagesTesting The Reliability of The Measures CronbachVo Thi Viet TrinhNo ratings yet
- Đề KTL Rà soát 3Document3 pagesĐề KTL Rà soát 3bab3cuteNo ratings yet
- KIEMTRATHONGKEUDDocument5 pagesKIEMTRATHONGKEUD2154110207nganNo ratings yet
- chuong4 kết quả nghiên cứu và thảo luậnDocument15 pageschuong4 kết quả nghiên cứu và thảo luậnthanhthan52hzNo ratings yet
- Đánh giá của nhân viên về công tác tuyển dụng tại công ty TNHH TM & DV Bia Sài Gòn Bình TâyDocument24 pagesĐánh giá của nhân viên về công tác tuyển dụng tại công ty TNHH TM & DV Bia Sài Gòn Bình TâyHoangtrungNo ratings yet
- BÀI QUÁ TRÌNH SỐ 3 finalDocument18 pagesBÀI QUÁ TRÌNH SỐ 3 finalTran Trung QuanNo ratings yet
- Chương 4 - N9Document23 pagesChương 4 - N9lgbao1334No ratings yet
- ĐỀ THI KTLDocument6 pagesĐỀ THI KTLhoang191010No ratings yet
- Biểu đồ và phân tích dữ liệu spssDocument11 pagesBiểu đồ và phân tích dữ liệu spssHuy GiaNo ratings yet
- BÀI TẬP THỰC HÀNH NGHIÊN CỨU MARKETINGDocument19 pagesBÀI TẬP THỰC HÀNH NGHIÊN CỨU MARKETINGNGUYỄN THỊ KIM CHINo ratings yet
- Chương 7 Phan Tich Va Xu Ly Du LieuDocument47 pagesChương 7 Phan Tich Va Xu Ly Du Lieuphungnguynnguyn26012003No ratings yet
- CUỐI KÌ - PHÂN TÍCH NHÂN TỐDocument2 pagesCUỐI KÌ - PHÂN TÍCH NHÂN TỐVi TrầnNo ratings yet
- Chương 3 còn lại cuốiDocument13 pagesChương 3 còn lại cuốiHương Nguyễn ThịNo ratings yet
- Thư TDocument1 pageThư TMy KidsNo ratings yet
- SpssDocument9 pagesSpssKỳ PhạmNo ratings yet
- Đề KTL Rà soát 1Document6 pagesĐề KTL Rà soát 1bab3cuteNo ratings yet
- Báo Cáo Mẫu 4 (9.5 Điểm)Document61 pagesBáo Cáo Mẫu 4 (9.5 Điểm)Prosie VNo ratings yet
- Bài tập chương 2 - Solution - updatedDocument9 pagesBài tập chương 2 - Solution - updatedThy PhạmNo ratings yet
- Chương 7. Phân tích và xử lý dữ liệuDocument90 pagesChương 7. Phân tích và xử lý dữ liệuNguyễn NhưNo ratings yet
- BT - KTL Chuong 1Document4 pagesBT - KTL Chuong 1Quang Khải ĐinhNo ratings yet
- 17.E KTL - CLC - GE06 - ThầyDocument2 pages17.E KTL - CLC - GE06 - Thầy050610220479No ratings yet
- 4.4 NCTTDocument3 pages4.4 NCTTvonguyenthuha2004thdNo ratings yet
- K214051670 - Trần Thanh Nhã - HWC4 - 4.5Document7 pagesK214051670 - Trần Thanh Nhã - HWC4 - 4.5Trần Thanh NhãNo ratings yet
- SPSS For Data AnalysisDocument5 pagesSPSS For Data AnalysisTú LêNo ratings yet
- Báo Cáo XSTKDocument75 pagesBáo Cáo XSTKNguyễn Thanh Tú100% (1)
- Bản Sao Nhóm-06-Đồ-án-nghiên-cứu-TCNH 2Document3 pagesBản Sao Nhóm-06-Đồ-án-nghiên-cứu-TCNH 2nguyenthingochien13092004No ratings yet
- Chuong10-PhiThamSo R HongNhungDocument12 pagesChuong10-PhiThamSo R HongNhungThu PhươngNo ratings yet
- Bài Kiểm Tra Số 2 - biDocument13 pagesBài Kiểm Tra Số 2 - biBi Hoàng ThúyNo ratings yet
- Báo Cáo Mẫu 4 (9.5 Điểm)Document63 pagesBáo Cáo Mẫu 4 (9.5 Điểm)Prosie VNo ratings yet
- Phần giới thiệu a,bDocument9 pagesPhần giới thiệu a,bnguyenthituyet0983191523No ratings yet
- BÀI KIỂM TRA - Thứ 6 ca 4 - Xem lại lần làm thử 2Document14 pagesBÀI KIỂM TRA - Thứ 6 ca 4 - Xem lại lần làm thử 2Minh Thư0% (1)
- Các bước phân tích dữ liệuDocument6 pagesCác bước phân tích dữ liệuAnh Đỗ Đặng MinhNo ratings yet
- Hệ số Cronbach's Alpha của các thang đo trong mô hìnhDocument12 pagesHệ số Cronbach's Alpha của các thang đo trong mô hìnhNhiNo ratings yet
- Hướng Dẫn Làm Báo Cáo Nghiên Cứu MarketingDocument14 pagesHướng Dẫn Làm Báo Cáo Nghiên Cứu MarketingBảo Trần Xuân TônNo ratings yet
- EFA and CFADocument16 pagesEFA and CFALộc Cao XuânNo ratings yet
- Bảng đọc (tạm thời)Document10 pagesBảng đọc (tạm thời)Phuong Anh DongNo ratings yet
- PHÂN TÍCH KẾT QUẢ KIỂM ĐỊNH CRONBACH'S ALPHADocument5 pagesPHÂN TÍCH KẾT QUẢ KIỂM ĐỊNH CRONBACH'S ALPHAhanttb22No ratings yet
- CK03 Phạm Nguyễn Sơn BìnhDocument45 pagesCK03 Phạm Nguyễn Sơn Bìnhbinh.trinhdnNo ratings yet
- SIU - Bài giữa kỳ - Thống kê ứng dụngDocument9 pagesSIU - Bài giữa kỳ - Thống kê ứng dụngÂn ÂnNo ratings yet
- Phân Tích H I QuyDocument6 pagesPhân Tích H I QuyVinh DanhNo ratings yet
- EFA WordDocument4 pagesEFA WordTHANH NGUYEN HOANGNo ratings yet
- DE 2018 Mau1Document10 pagesDE 2018 Mau1Thanh Nguyễn Thị HồngNo ratings yet
- De Thi BTL KTL HK Cuoi 2021Document3 pagesDe Thi BTL KTL HK Cuoi 2021tranthumai3011No ratings yet
- Huong Dan Doc Ket Qua Nghien Cuu - Nhom Cua HangDocument7 pagesHuong Dan Doc Ket Qua Nghien Cuu - Nhom Cua HangMinh AnhNo ratings yet
- Phân Tích Kết Quả Kiểm Định Cronbach's AlphaDocument9 pagesPhân Tích Kết Quả Kiểm Định Cronbach's Alphahanttb22No ratings yet
- Full Tai Lieu Kinh Te LuongDocument154 pagesFull Tai Lieu Kinh Te LuongThy VõNo ratings yet
- Đề số 02Document1 pageĐề số 02Thư Mai Nguyễn Thị AnhNo ratings yet
- Hoàng Anh Quốc - Bài Tập SPSSDocument13 pagesHoàng Anh Quốc - Bài Tập SPSSQUỐC HOÀNG ANHNo ratings yet
- Tran Nguyen Nhat Tien 04102002Document36 pagesTran Nguyen Nhat Tien 04102002TIẾN TRẦN NGUYỄN NHẬTNo ratings yet